DFormer: Diffusion-guided Transformer for Universal Image Segmentation
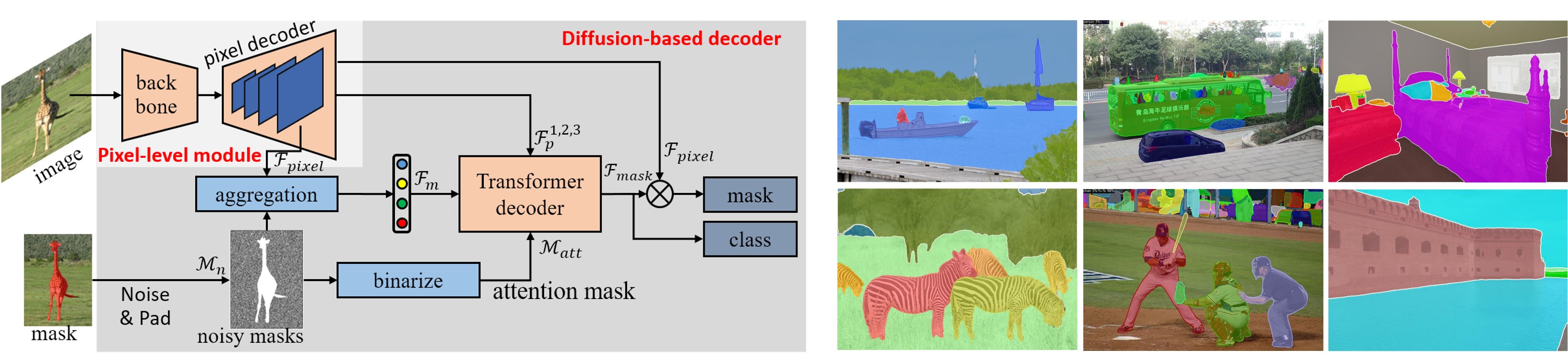
This paper introduces an approach, named DFormer, for universal image segmentation. The proposed DFormer views universal image segmentation task as a denoising process using a diffusion model. DFormer first adds various levels of Gaussian noise to ground-truth masks, and then learns a model to predict denoising masks from corrupted masks. Specifically, we take deep pixel-level features along with the noisy masks as inputs to generate mask features and attention masks, employing diffusion-based decoder to perform mask prediction gradually. At inference, our DFormer directly predicts the masks and corresponding categories from a set of randomly-generated masks. Extensive experiments reveal the merits of our proposed contributions on different image segmentation tasks: panoptic segmentation, instance segmentation, and semantic segmentation. Our DFormer outperforms the recent diffusion-based panoptic segmentation method Pix2Seq-D with a gain of 3.6% on MS COCO val2017 set. Further, DFormer achieves promising semantic segmentation performance outperforming the recent diffusion-based method by 2.2% on ADE20K val set. Our source code and models will be publicly on https://github.com/cp3wan/DFormer
PDF Abstract





 MS COCO
MS COCO
 ADE20K
ADE20K
