Detect Everything with Few Examples
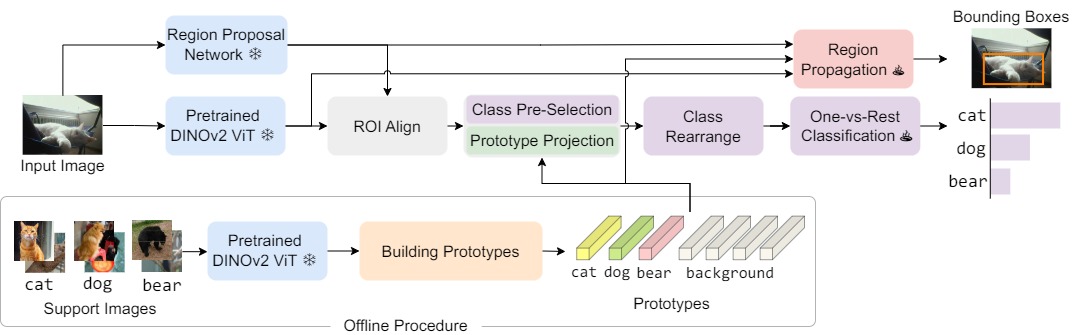
Few-shot object detection aims at detecting novel categories given a few example images. Recent methods focus on finetuning strategies, with complicated procedures that prohibit a wider application. In this paper, we introduce DE-ViT, a few-shot object detector without the need for finetuning. DE-ViT's novel architecture is based on a new region-propagation mechanism for localization. The propagated region masks are transformed into bounding boxes through a learnable spatial integral layer. Instead of training prototype classifiers, we propose to use prototypes to project ViT features into a subspace that is robust to overfitting on base classes. We evaluate DE-ViT on few-shot, and one-shot object detection benchmarks with Pascal VOC, COCO, and LVIS. DE-ViT establishes new state-of-the-art results on all benchmarks. Notably, for COCO, DE-ViT surpasses the few-shot SoTA by 15 mAP on 10-shot and 7.2 mAP on 30-shot and one-shot SoTA by 2.8 AP50. For LVIS, DE-ViT outperforms few-shot SoTA by 20 box APr.
PDF AbstractCode






 MS COCO
MS COCO
 ADE20K
ADE20K
 LVIS
LVIS
 COCO-Stuff
COCO-Stuff
 FSOD
FSOD
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Open Vocabulary Object Detection | LVIS v1.0 | DE-ViT | AP novel-LVIS base training | 34.3 | # 4 | |
| Open Vocabulary Object Detection | MSCOCO | DE-ViT | AP 0.5 | 50 | # 2 | |
| One-Shot Object Detection | MS COCO | DE-ViT | AP 0.5 | 28.4 | # 2 | |
| Few-Shot Object Detection | MS-COCO (10-shot) | DE-ViT | AP | 34.0 | # 1 | |
| Few-Shot Object Detection | MS-COCO (30-shot) | DE-ViT | AP | 34 | # 1 |
