Detaching and Boosting: Dual Engine for Scale-Invariant Self-Supervised Monocular Depth Estimation
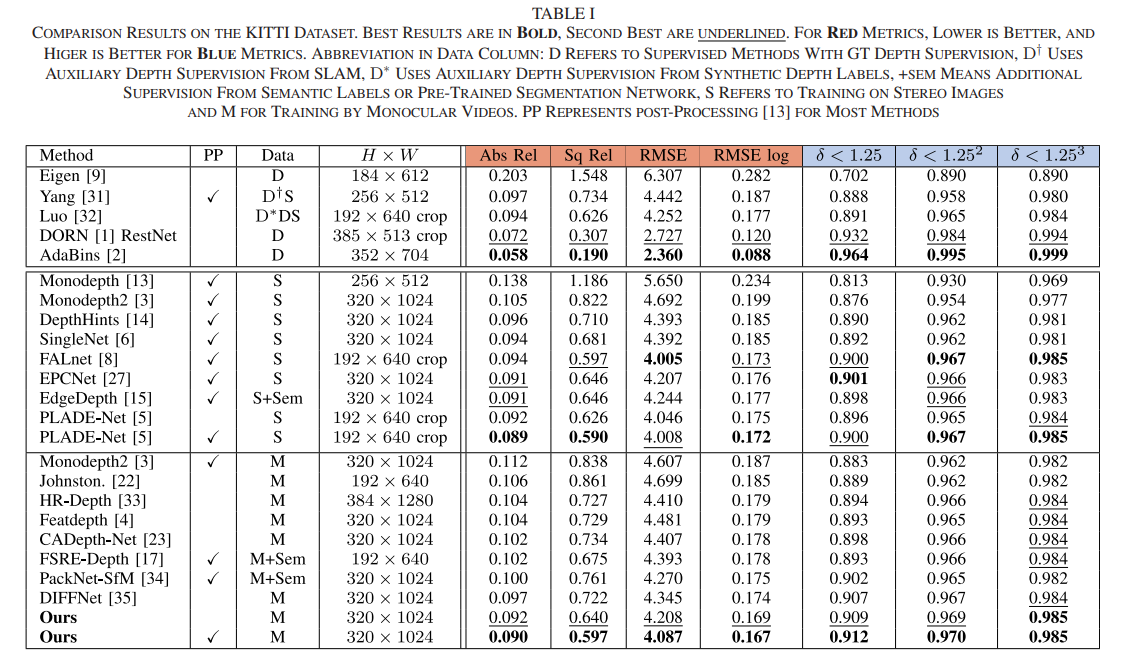
Monocular depth estimation (MDE) in the self-supervised scenario has emerged as a promising method as it refrains from the requirement of ground truth depth. Despite continuous efforts, MDE is still sensitive to scale changes especially when all the training samples are from one single camera. Meanwhile, it deteriorates further since camera movement results in heavy coupling between the predicted depth and the scale change. In this paper, we present a scale-invariant approach for self-supervised MDE, in which scale-sensitive features (SSFs) are detached away while scale-invariant features (SIFs) are boosted further. To be specific, a simple but effective data augmentation by imitating the camera zooming process is proposed to detach SSFs, making the model robust to scale changes. Besides, a dynamic cross-attention module is designed to boost SIFs by fusing multi-scale cross-attention features adaptively. Extensive experiments on the KITTI dataset demonstrate that the detaching and boosting strategies are mutually complementary in MDE and our approach achieves new State-of-The-Art performance against existing works from 0.097 to 0.090 w.r.t absolute relative error. The code will be made public soon.
PDF Abstract



 KITTI
KITTI
