DeMT: Deformable Mixer Transformer for Multi-Task Learning of Dense Prediction
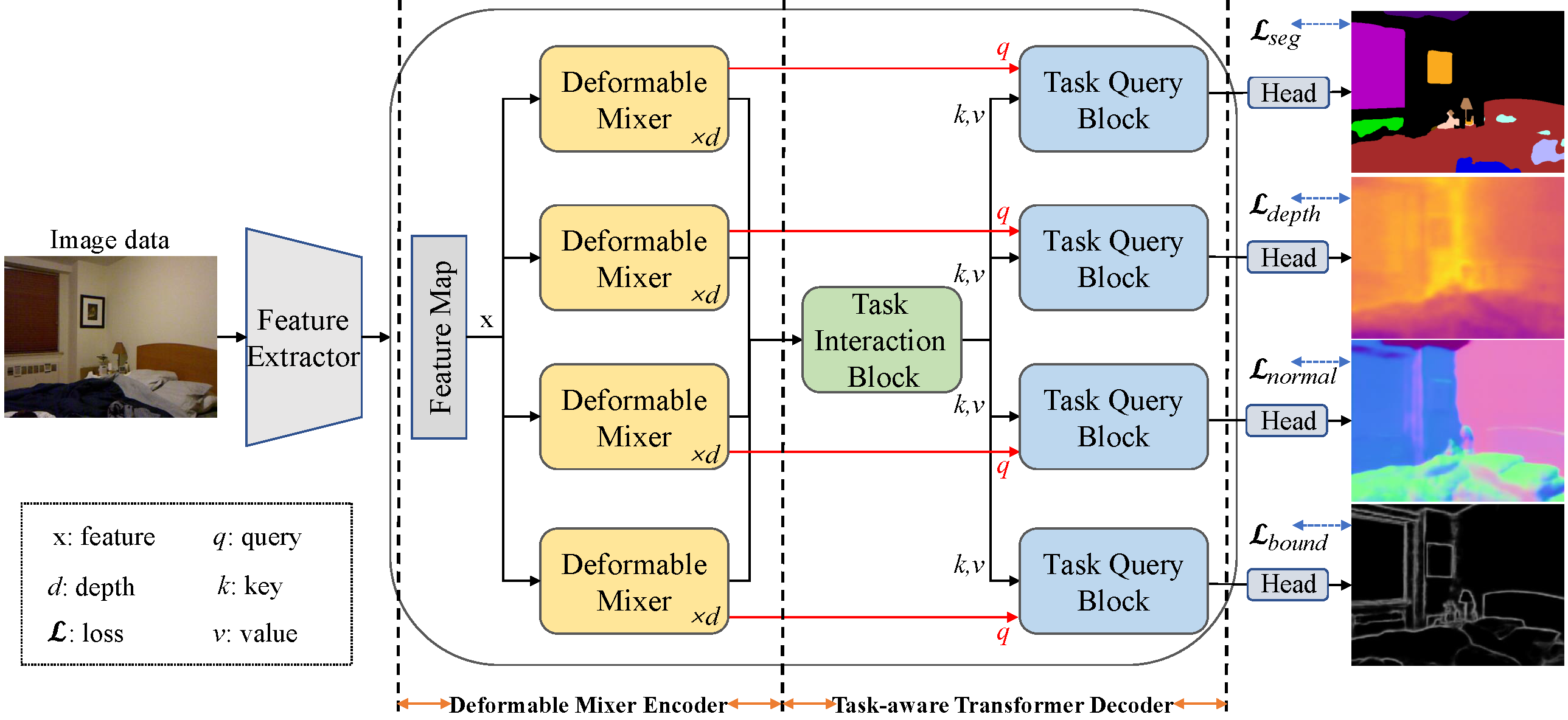
Convolution neural networks (CNNs) and Transformers have their own advantages and both have been widely used for dense prediction in multi-task learning (MTL). Most of the current studies on MTL solely rely on CNN or Transformer. In this work, we present a novel MTL model by combining both merits of deformable CNN and query-based Transformer for multi-task learning of dense prediction. Our method, named DeMT, is based on a simple and effective encoder-decoder architecture (i.e., deformable mixer encoder and task-aware transformer decoder). First, the deformable mixer encoder contains two types of operators: the channel-aware mixing operator leveraged to allow communication among different channels ($i.e.,$ efficient channel location mixing), and the spatial-aware deformable operator with deformable convolution applied to efficiently sample more informative spatial locations (i.e., deformed features). Second, the task-aware transformer decoder consists of the task interaction block and task query block. The former is applied to capture task interaction features via self-attention. The latter leverages the deformed features and task-interacted features to generate the corresponding task-specific feature through a query-based Transformer for corresponding task predictions. Extensive experiments on two dense image prediction datasets, NYUD-v2 and PASCAL-Context, demonstrate that our model uses fewer GFLOPs and significantly outperforms current Transformer- and CNN-based competitive models on a variety of metrics. The code are available at https://github.com/yangyangxu0/DeMT .
PDF Abstract


