Delving Deeper into the Decoder for Video Captioning
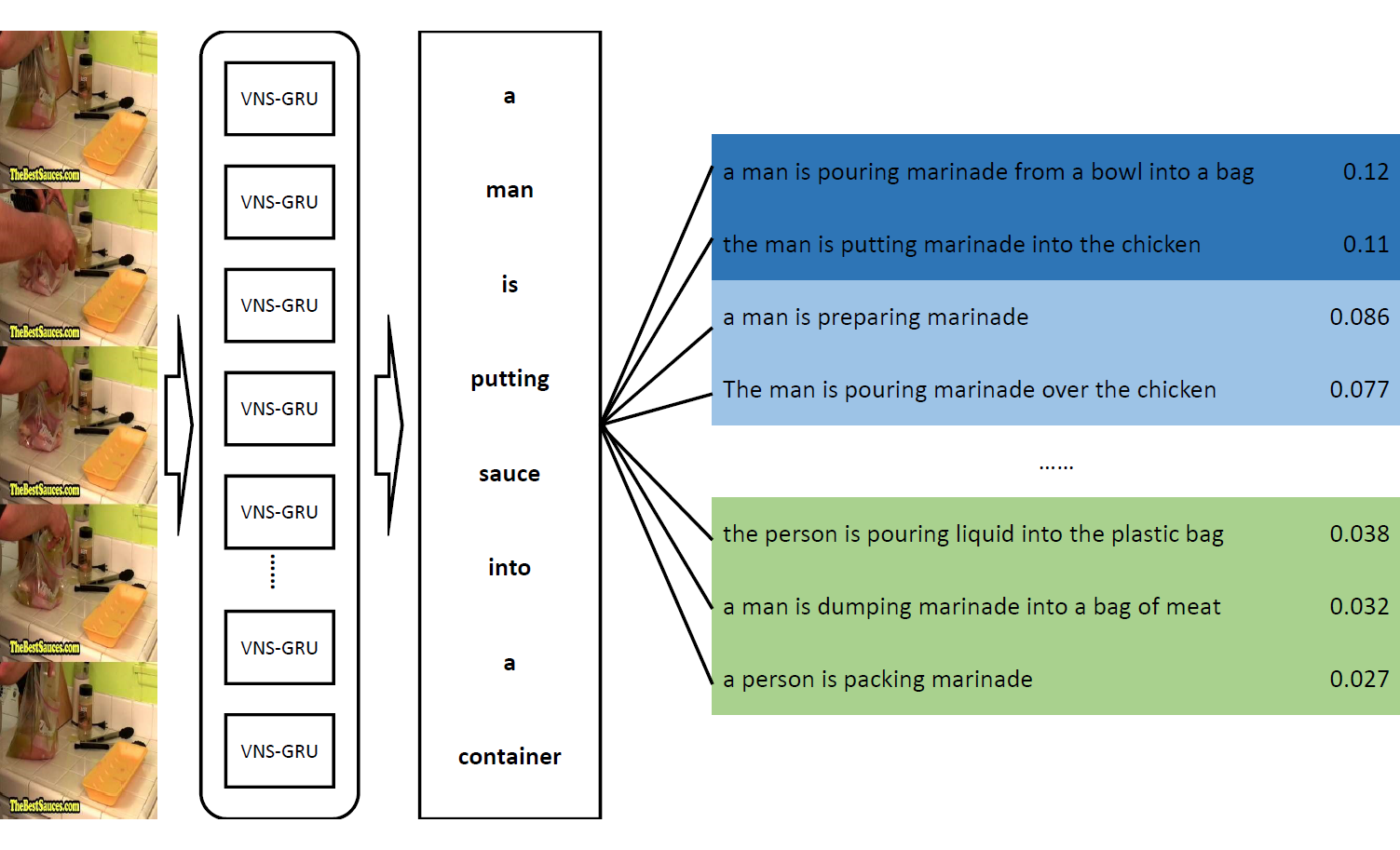
Video captioning is an advanced multi-modal task which aims to describe a video clip using a natural language sentence. The encoder-decoder framework is the most popular paradigm for this task in recent years. However, there exist some problems in the decoder of a video captioning model. We make a thorough investigation into the decoder and adopt three techniques to improve the performance of the model. First of all, a combination of variational dropout and layer normalization is embedded into a recurrent unit to alleviate the problem of overfitting. Secondly, a new online method is proposed to evaluate the performance of a model on a validation set so as to select the best checkpoint for testing. Finally, a new training strategy called professional learning is proposed which uses the strengths of a captioning model and bypasses its weaknesses. It is demonstrated in the experiments on Microsoft Research Video Description Corpus (MSVD) and MSR-Video to Text (MSR-VTT) datasets that our model has achieved the best results evaluated by BLEU, CIDEr, METEOR and ROUGE-L metrics with significant gains of up to 18% on MSVD and 3.5% on MSR-VTT compared with the previous state-of-the-art models.
PDF Abstract

 MSR-VTT
MSR-VTT
