Deficiency-Aware Masked Transformer for Video Inpainting
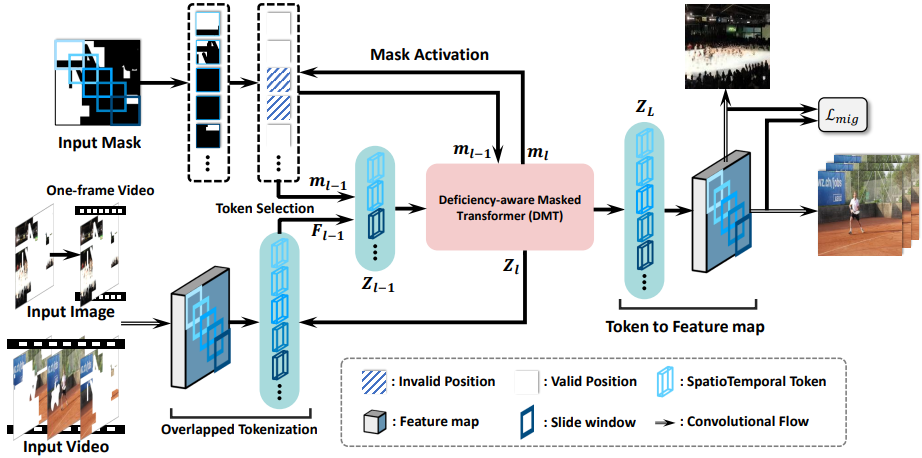
Recent video inpainting methods have made remarkable progress by utilizing explicit guidance, such as optical flow, to propagate cross-frame pixels. However, there are cases where cross-frame recurrence of the masked video is not available, resulting in a deficiency. In such situation, instead of borrowing pixels from other frames, the focus of the model shifts towards addressing the inverse problem. In this paper, we introduce a dual-modality-compatible inpainting framework called Deficiency-aware Masked Transformer (DMT), which offers three key advantages. Firstly, we pretrain a image inpainting model DMT_img serve as a prior for distilling the video model DMT_vid, thereby benefiting the hallucination of deficiency cases. Secondly, the self-attention module selectively incorporates spatiotemporal tokens to accelerate inference and remove noise signals. Thirdly, a simple yet effective Receptive Field Contextualizer is integrated into DMT, further improving performance. Extensive experiments conducted on YouTube-VOS and DAVIS datasets demonstrate that DMT_vid significantly outperforms previous solutions. The code and video demonstrations can be found at github.com/yeates/DMT.
PDF Abstract



 DAVIS
DAVIS
 YouTube-VOS 2018
YouTube-VOS 2018

