Classification of Macromolecule Type Based on Sequences of Amino Acids Using Deep Learning
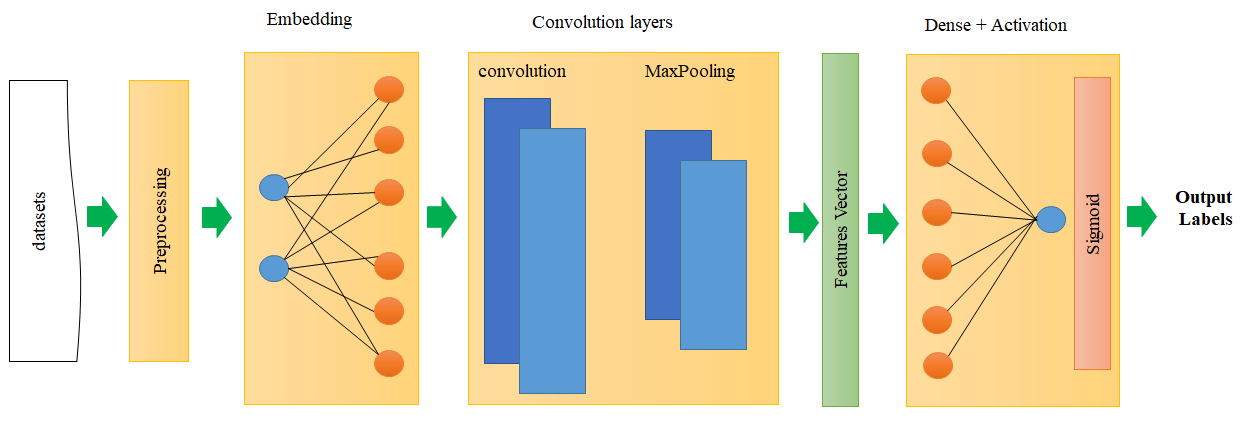
The classification of amino acids and their sequence analysis plays a vital role in life sciences and is a challenging task. This article uses and compares state-of-the-art deep learning models like convolution neural networks (CNN), long short-term memory (LSTM), and gated recurrent units (GRU) to solve macromolecule classification problems using amino acids. These models have efficient frameworks for solving a broad spectrum of complex learning problems compared to traditional machine learning techniques. We use word embedding to represent the amino acid sequences as vectors. The CNN extracts features from amino acid sequences, which are treated as vectors, then fed to the models mentioned above to train a robust classifier. Our results show that word2vec as embedding combined with VGG-16 performs better than LSTM and GRU. The proposed approach gets an error rate of 1.5%.
PDF Abstract
