Deep speech inpainting of time-frequency masks
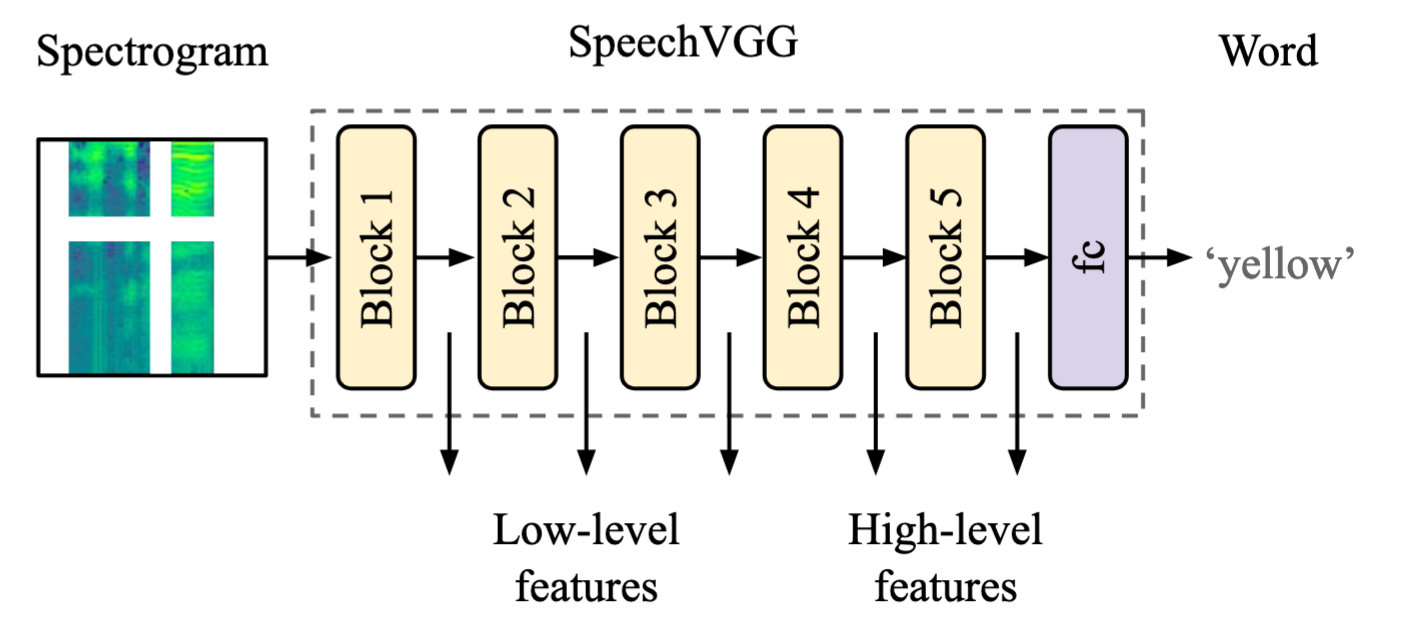
Transient loud intrusions, often occurring in noisy environments, can completely overpower speech signal and lead to an inevitable loss of information. While existing algorithms for noise suppression can yield impressive results, their efficacy remains limited for very low signal-to-noise ratios or when parts of the signal are missing. To address these limitations, here we propose an end-to-end framework for speech inpainting, the context-based retrieval of missing or severely distorted parts of time-frequency representation of speech. The framework is based on a convolutional U-Net trained via deep feature losses, obtained using speechVGG, a deep speech feature extractor pre-trained on an auxiliary word classification task. Our evaluation results demonstrate that the proposed framework can recover large portions of missing or distorted time-frequency representation of speech, up to 400 ms and 3.2 kHz in bandwidth. In particular, our approach provided a substantial increase in STOI & PESQ objective metrics of the initially corrupted speech samples. Notably, using deep feature losses to train the framework led to the best results, as compared to conventional approaches.
PDF Abstract

 ImageNet
ImageNet
