Deep Learning Technique for Human Parsing: A Survey and Outlook
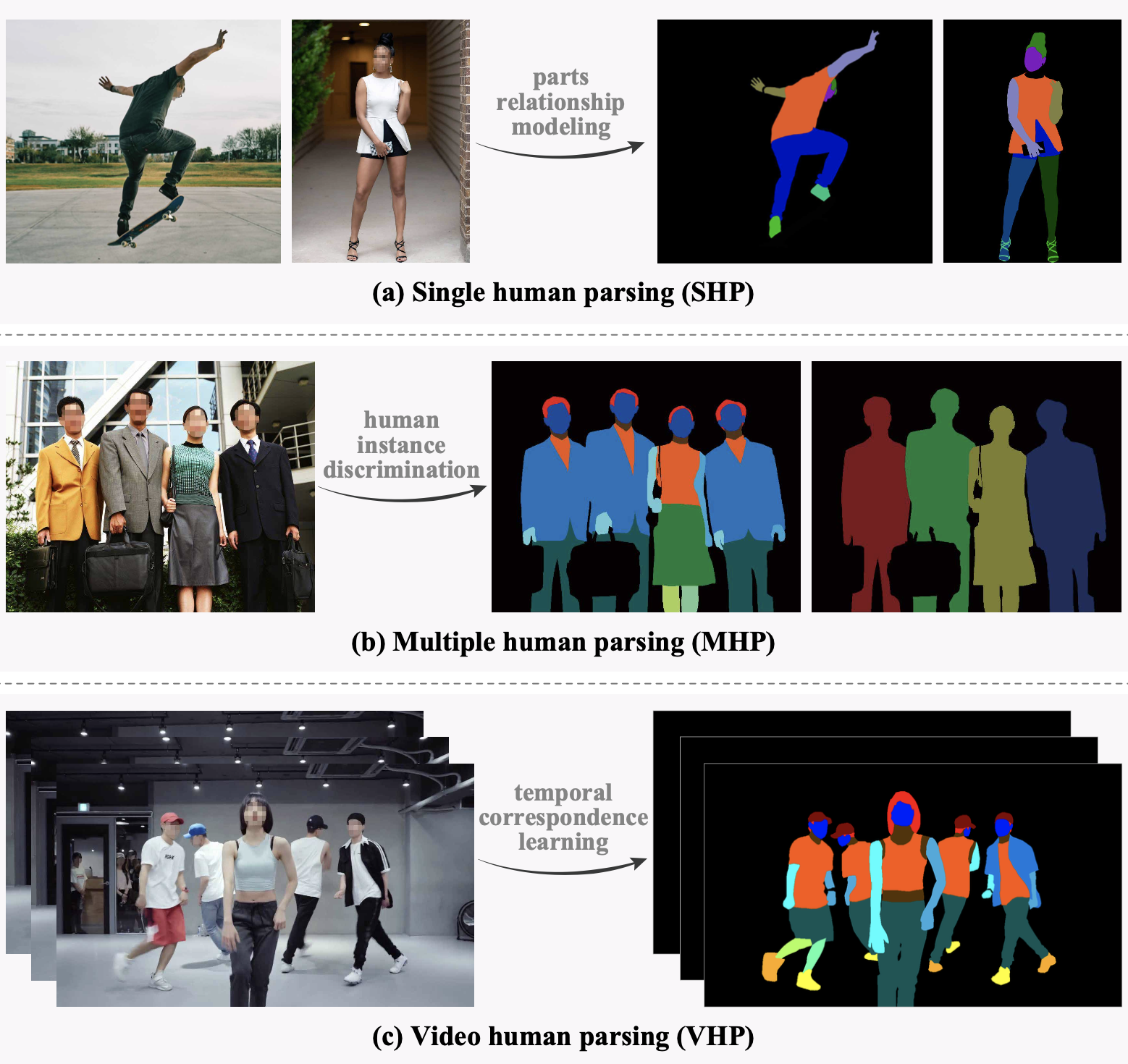
Human parsing aims to partition humans in image or video into multiple pixel-level semantic parts. In the last decade, it has gained significantly increased interest in the computer vision community and has been utilized in a broad range of practical applications, from security monitoring, to social media, to visual special effects, just to name a few. Although deep learning-based human parsing solutions have made remarkable achievements, many important concepts, existing challenges, and potential research directions are still confusing. In this survey, we comprehensively review three core sub-tasks: single human parsing, multiple human parsing, and video human parsing, by introducing their respective task settings, background concepts, relevant problems and applications, representative literature, and datasets. We also present quantitative performance comparisons of the reviewed methods on benchmark datasets. Additionally, to promote sustainable development of the community, we put forward a transformer-based human parsing framework, providing a high-performance baseline for follow-up research through universal, concise, and extensible solutions. Finally, we point out a set of under-investigated open issues in this field and suggest new directions for future study. We also provide a regularly updated project page, to continuously track recent developments in this fast-advancing field: https://github.com/soeaver/awesome-human-parsing.
PDF Abstract

 MS COCO
MS COCO
 Cityscapes
Cityscapes
 DensePose
DensePose
 LIP
LIP
 DeepFashion2
DeepFashion2
 CIHP
CIHP
 ModaNet
ModaNet
 MHP
MHP
