Decoupling Value and Policy for Generalization in Reinforcement Learning
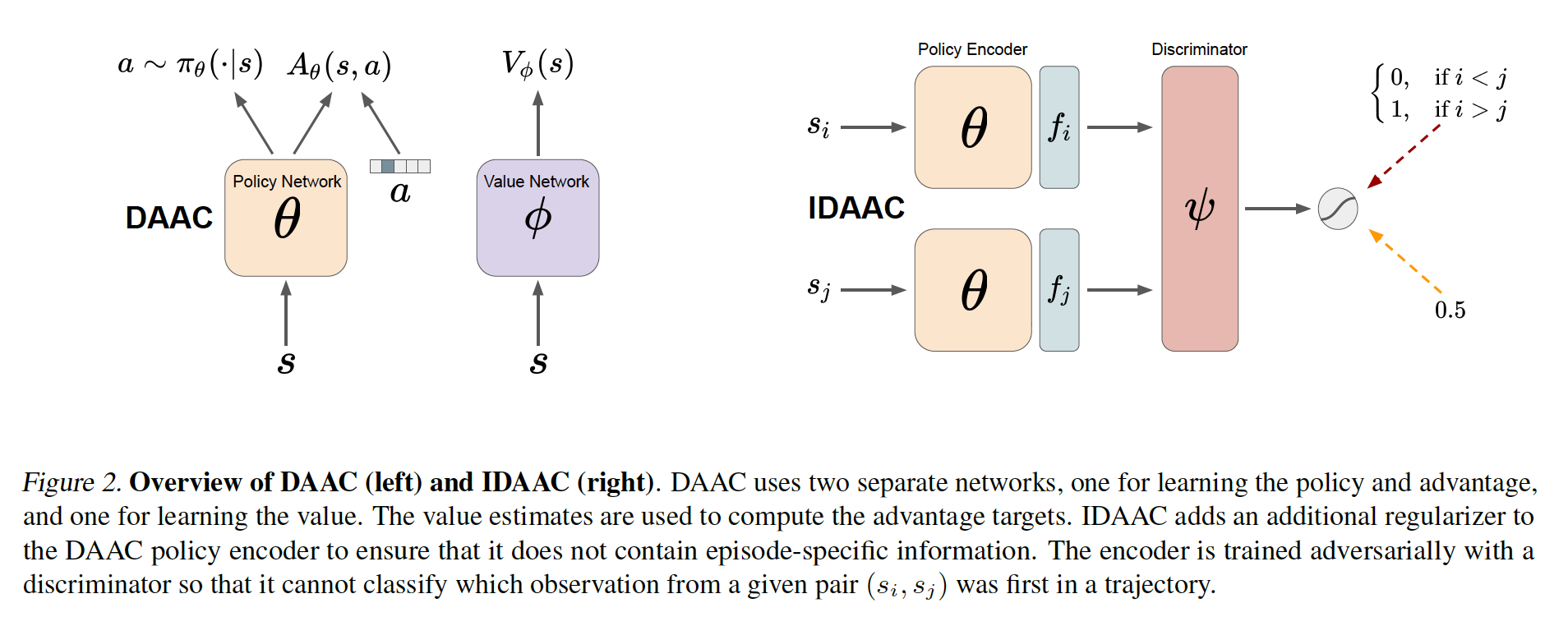
Standard deep reinforcement learning algorithms use a shared representation for the policy and value function, especially when training directly from images. However, we argue that more information is needed to accurately estimate the value function than to learn the optimal policy. Consequently, the use of a shared representation for the policy and value function can lead to overfitting. To alleviate this problem, we propose two approaches which are combined to create IDAAC: Invariant Decoupled Advantage Actor-Critic. First, IDAAC decouples the optimization of the policy and value function, using separate networks to model them. Second, it introduces an auxiliary loss which encourages the representation to be invariant to task-irrelevant properties of the environment. IDAAC shows good generalization to unseen environments, achieving a new state-of-the-art on the Procgen benchmark and outperforming popular methods on DeepMind Control tasks with distractors. Our implementation is available at https://github.com/rraileanu/idaac.
PDF Abstract

 DeepMind Control Suite
DeepMind Control Suite
 ProcGen
ProcGen
