decoupleQ: Towards 2-bit Post-Training Uniform Quantization via decoupling Parameters into Integer and Floating Points
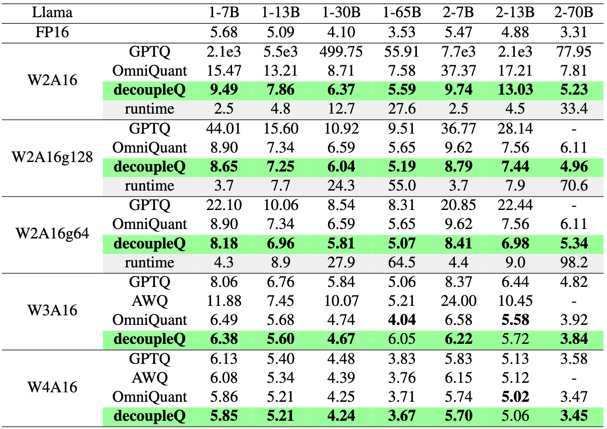
Quantization emerges as one of the most promising compression technologies for deploying efficient large models for various real time application in recent years. Considering that the storage and IO of weights take up the vast majority of the overhead inside a large model, weight only quantization can lead to large gains. However, existing quantization schemes suffer from significant accuracy degradation at very low bits, or require some additional computational overhead when deployed, making it difficult to be applied to large-scale applications in industry. In this paper, we propose decoupleQ, achieving a substantial increase in model accuracy, especially at very low bits. decoupleQ abandons the traditional heuristic quantization paradigm and decouples the model parameters into integer and floating-point parts, thus transforming the quantization problem into a traditional mathematical optimization problem with constraints, which is then solved alternatively by off-the-shelf optimization methods. Quantization via decoupleQ is linear and uniform, making it hardware-friendlier than non-uniform counterpart, and enabling the idea to be migrated to high-bit quantization to enhance its robustness. Our method has achieved well on-line accuracy near fp16/bf16 on the 2-bit quantization of large speech models in ByteDance. The code is available at https://github.com/bytedance/decoupleQ
PDF Abstract

 ImageNet
ImageNet
 WikiText-2
WikiText-2
 C4
C4
