Decentralized Federated Policy Gradient with Byzantine Fault-Tolerance and Provably Fast Convergence
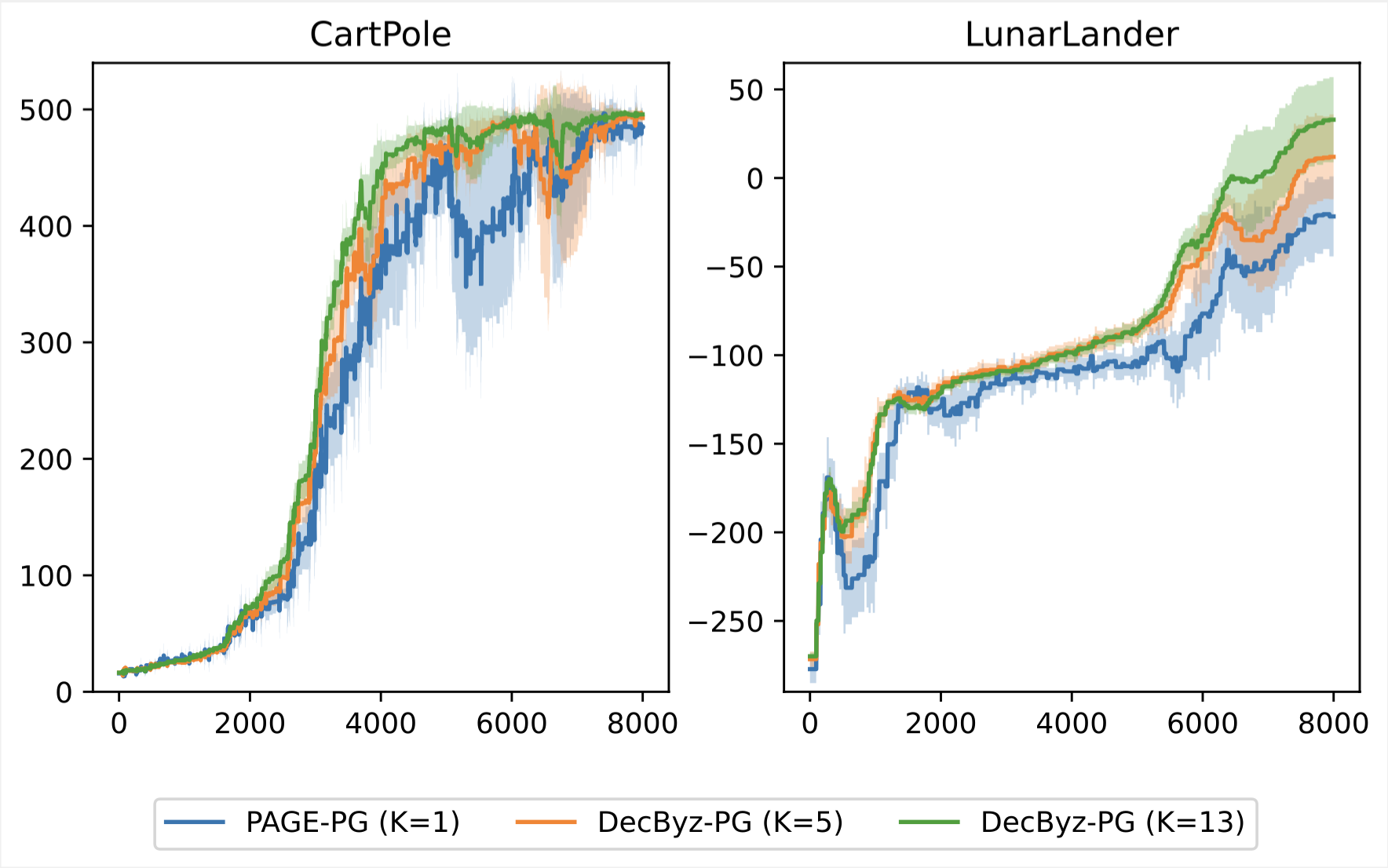
In Federated Reinforcement Learning (FRL), agents aim to collaboratively learn a common task, while each agent is acting in its local environment without exchanging raw trajectories. Existing approaches for FRL either (a) do not provide any fault-tolerance guarantees (against misbehaving agents), or (b) rely on a trusted central agent (a single point of failure) for aggregating updates. We provide the first decentralized Byzantine fault-tolerant FRL method. Towards this end, we first propose a new centralized Byzantine fault-tolerant policy gradient (PG) algorithm that improves over existing methods by relying only on assumptions standard for non-fault-tolerant PG. Then, as our main contribution, we show how a combination of robust aggregation and Byzantine-resilient agreement methods can be leveraged in order to eliminate the need for a trusted central entity. Since our results represent the first sample complexity analysis for Byzantine fault-tolerant decentralized federated non-convex optimization, our technical contributions may be of independent interest. Finally, we corroborate our theoretical results experimentally for common RL environments, demonstrating the speed-up of decentralized federations w.r.t. the number of participating agents and resilience against various Byzantine attacks.
PDF Abstract
