Data Efficient Language-supervised Zero-shot Recognition with Optimal Transport Distillation
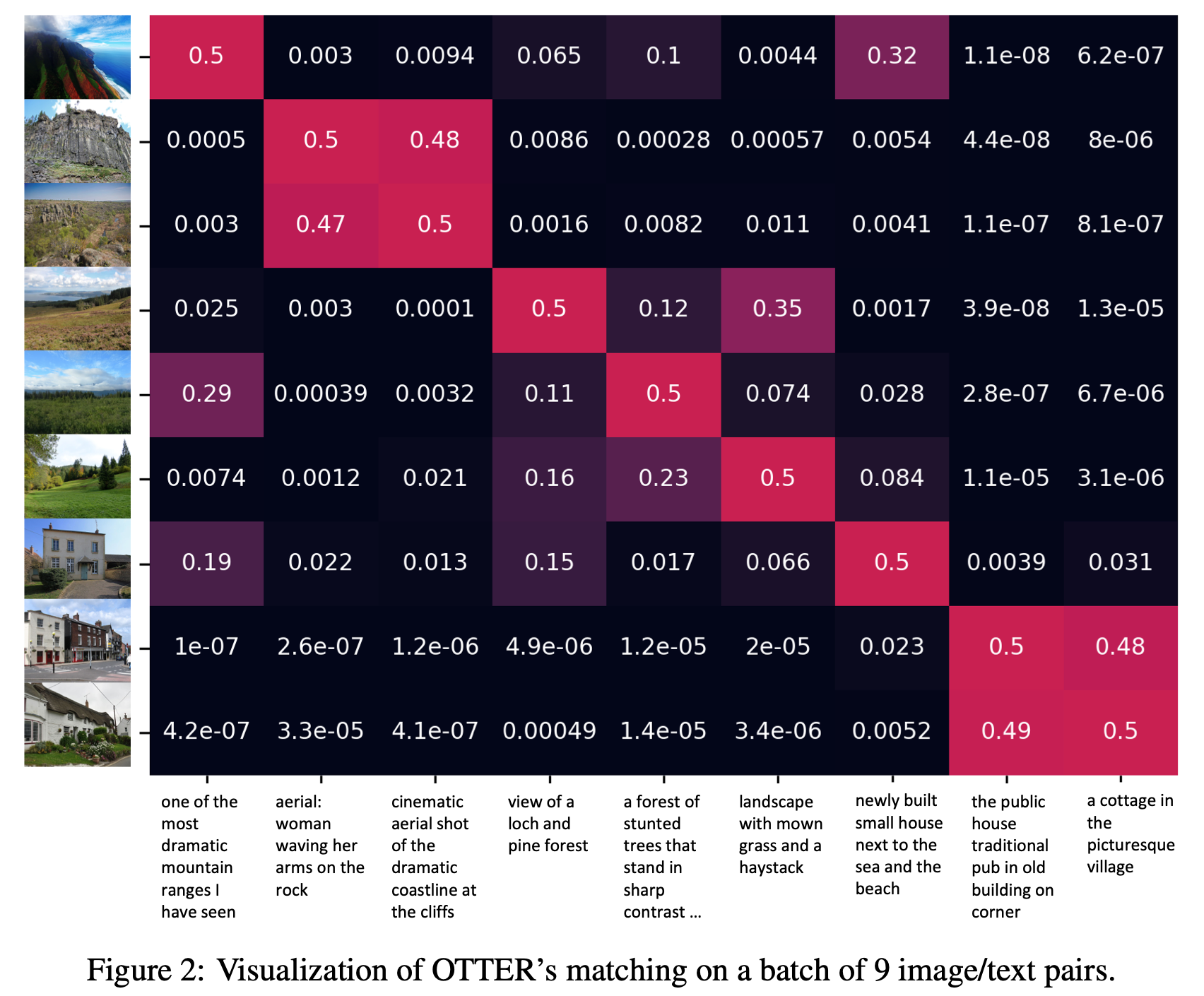
Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use InfoNCE loss to train a model to predict the pairing between images and text captions. CLIP, however, is data hungry and requires more than 400M image-text pairs for training. The inefficiency can be partially attributed to the fact that the image-text pairs are noisy. To address this, we propose OTTER (Optimal TransporT distillation for Efficient zero-shot Recognition), which uses online entropic optimal transport to find a soft image-text match as labels for contrastive learning. Based on pretrained image and text encoders, models trained with OTTER achieve strong performance with only 3M image text pairs. Compared with InfoNCE loss, label smoothing, and knowledge distillation, OTTER consistently outperforms these baselines in zero shot evaluation on Google Open Images (19,958 classes) and multi-labeled ImageNet 10K (10032 classes) from Tencent ML-Images. Over 42 evaluations on 7 different dataset/architecture settings x 6 metrics, OTTER outperforms (32) or ties (2) all baselines in 34 of them.
PDF Abstract ICLR 2022 PDF ICLR 2022 Abstract



 ImageNet
ImageNet
 Conceptual Captions
Conceptual Captions
 YFCC100M
YFCC100M
 WIT
WIT
 Tencent ML-Images
Tencent ML-Images
