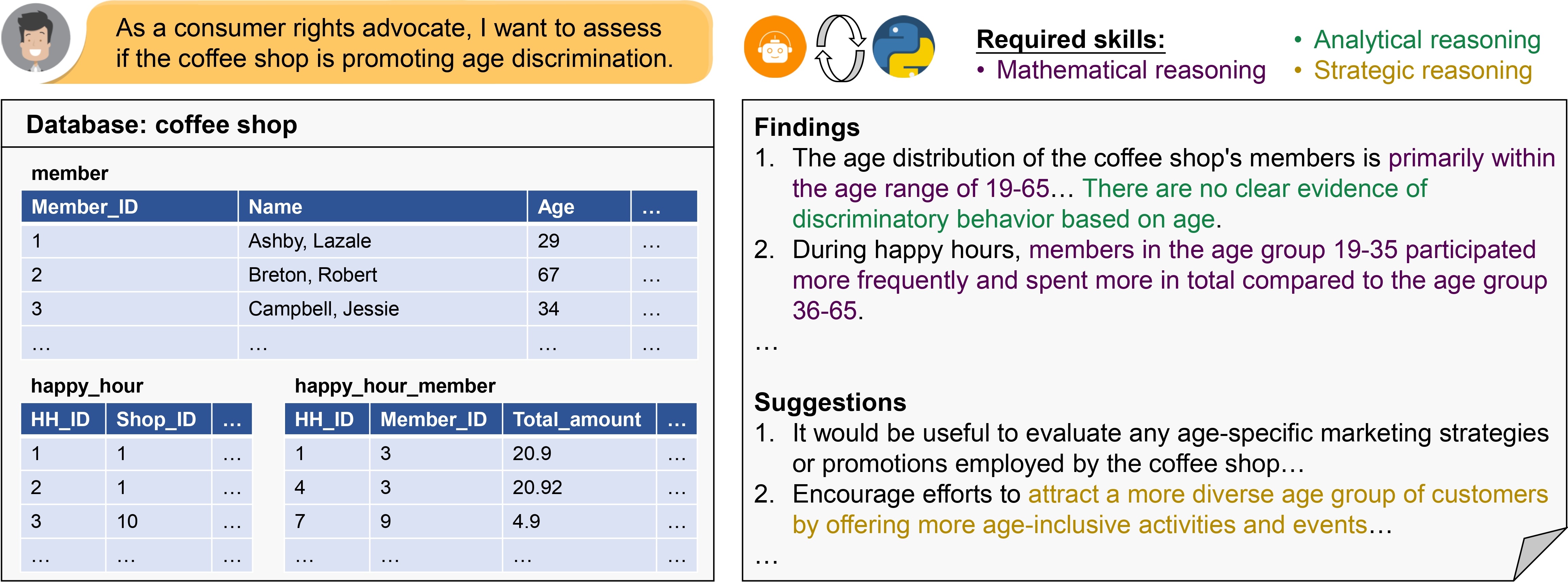
DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation
Data analysis is a crucial analytical process to generate in-depth studies and conclusive insights to comprehensively answer a given user query for tabular data. In this work, we aim to propose new resources and benchmarks to inspire future research on this crucial yet challenging and under-explored task. However, collecting data analysis annotations curated by experts can be prohibitively expensive. We propose to automatically generate high-quality answer annotations leveraging the code-generation capabilities of LLMs with a multi-turn prompting technique. We construct the DACO dataset, containing (1) 440 databases (of tabular data) collected from real-world scenarios, (2) ~2k query-answer pairs that can serve as weak supervision for model training, and (3) a concentrated but high-quality test set with human refined annotations that serves as our main evaluation benchmark. We train a 6B supervised fine-tuning (SFT) model on DACO dataset, and find that the SFT model learns reasonable data analysis capabilities. To further align the models with human preference, we use reinforcement learning to encourage generating analysis perceived by human as helpful, and design a set of dense rewards to propagate the sparse human preference reward to intermediate code generation steps. Our DACO-RL algorithm is evaluated by human annotators to produce more helpful answers than SFT model in 57.72% cases, validating the effectiveness of our proposed algorithm. Data and code are released at https://github.com/shirley-wu/daco
PDF Abstract

