CoCA: Fusing Position Embedding with Collinear Constrained Attention in Transformers for Long Context Window Extending
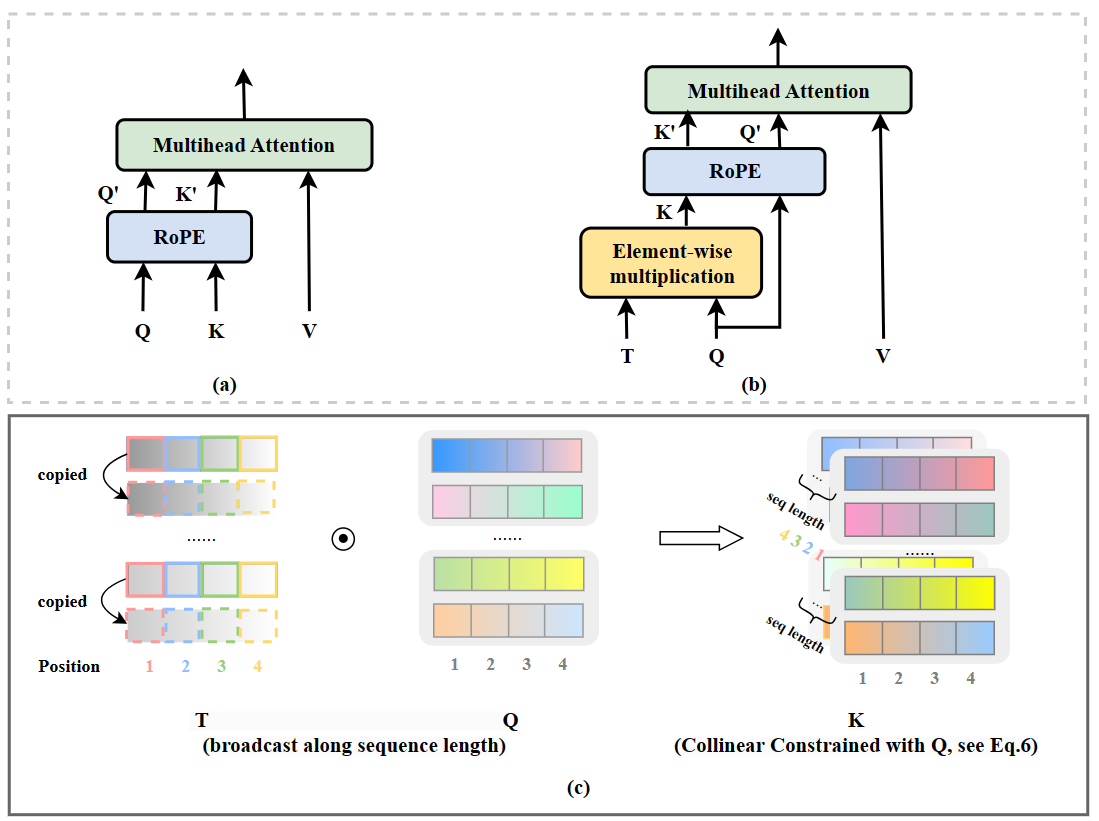
Self-attention and position embedding are two key modules in transformer-based Large Language Models (LLMs). However, the potential relationship between them is far from well studied, especially for long context window extending. In fact, anomalous behaviors harming long context extrapolation exist between Rotary Position Embedding (RoPE) and vanilla self-attention unveiled by our work. To address this issue, we propose a novel attention mechanism, CoCA (Collinear Constrained Attention). Specifically, we enforce a collinear constraint between $Q$ and $K$ to seamlessly integrate RoPE and self-attention. While only adding minimal computational and spatial complexity, this integration significantly enhances long context window extrapolation ability. We provide an optimized implementation, making it a drop-in replacement for any existing transformer-based models. Extensive experiments show that CoCA performs extraordinarily well in extending context windows. A CoCA-based GPT model, trained with a context length of 512, can seamlessly extend the context window up to 32K (60$\times$), without any fine-tuning. Additionally, by dropping CoCA in LLaMA-7B, we achieve extrapolation up to 32K within only 2K training length. Our code is publicly available at: https://github.com/codefuse-ai/Collinear-Constrained-Attention
PDF Abstract

