CTC-Segmentation of Large Corpora for German End-to-end Speech Recognition
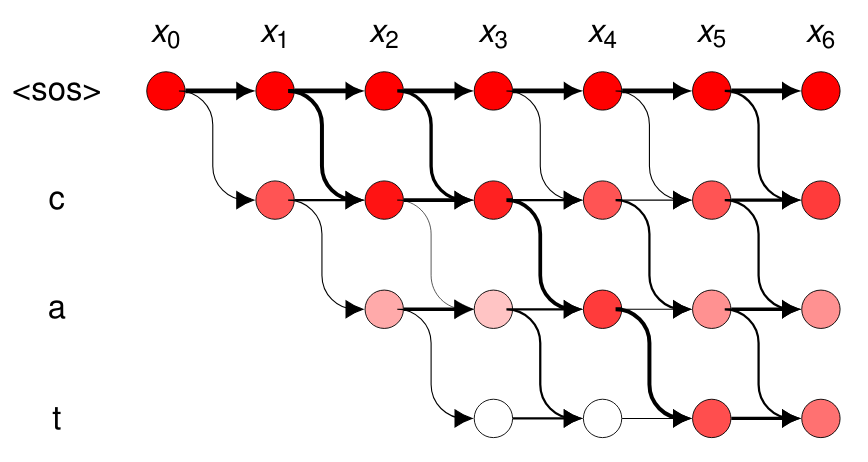
Recent end-to-end Automatic Speech Recognition (ASR) systems demonstrated the ability to outperform conventional hybrid DNN/ HMM ASR. Aside from architectural improvements in those systems, those models grew in terms of depth, parameters and model capacity. However, these models also require more training data to achieve comparable performance. In this work, we combine freely available corpora for German speech recognition, including yet unlabeled speech data, to a big dataset of over $1700$h of speech data. For data preparation, we propose a two-stage approach that uses an ASR model pre-trained with Connectionist Temporal Classification (CTC) to boot-strap more training data from unsegmented or unlabeled training data. Utterances are then extracted from label probabilities obtained from the network trained with CTC to determine segment alignments. With this training data, we trained a hybrid CTC/attention Transformer model that achieves $12.8\%$ WER on the Tuda-DE test set, surpassing the previous baseline of $14.4\%$ of conventional hybrid DNN/HMM ASR.
PDF AbstractCode

 Colab
Colab
 Spaces
Spaces

Tasks

Datasets
 Common Voice
Common Voice
Results from the Paper
 Ranked #5 on
Speech Recognition
on TUDA
(using extra training data)
Ranked #5 on
Speech Recognition
on TUDA
(using extra training data)
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Speech Recognition | TUDA | Hybrid CTC/Attention | Test WER | 12.8% | # 5 |
