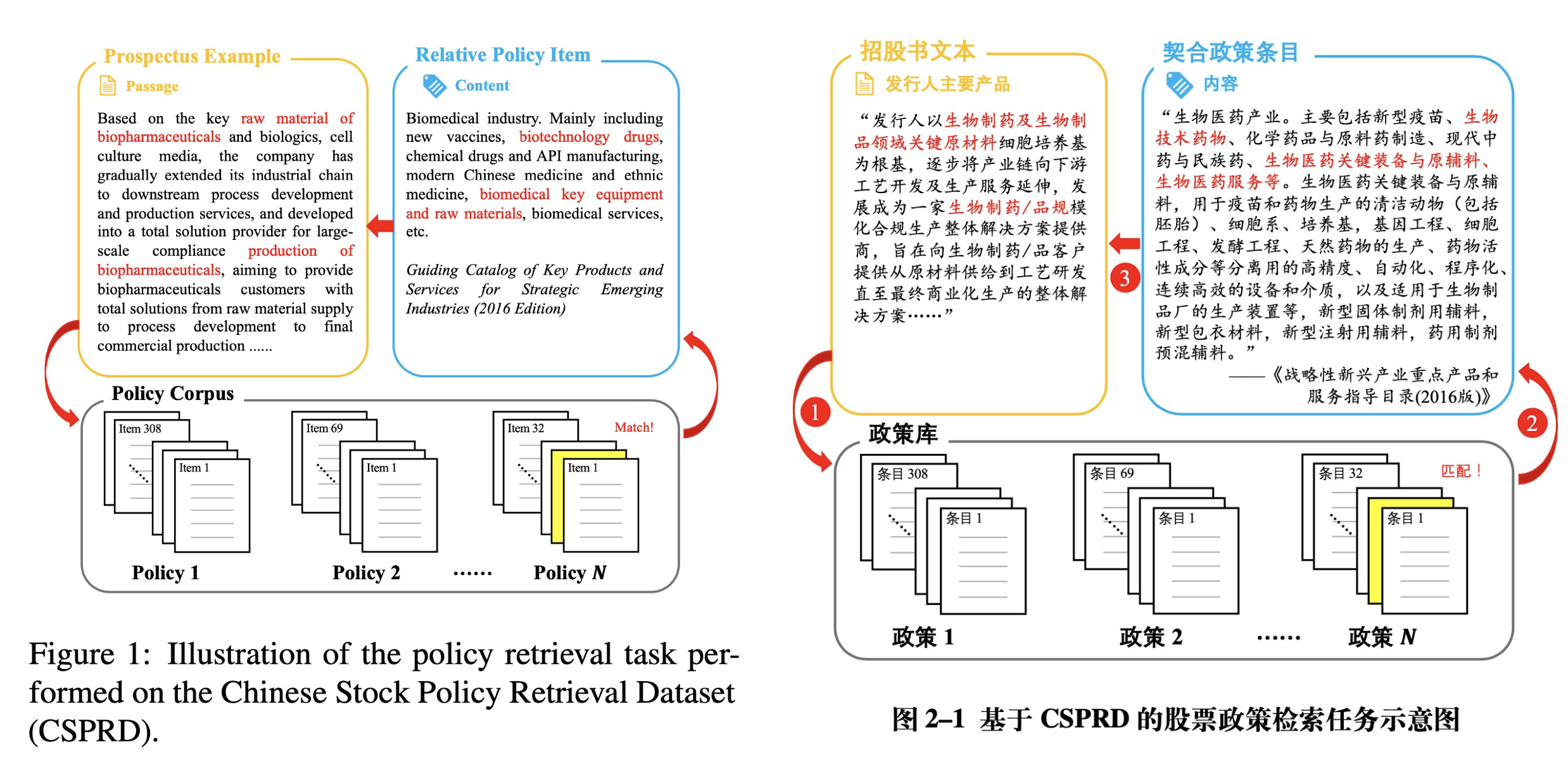
CSPRD: A Financial Policy Retrieval Dataset for Chinese Stock Market
In recent years, great advances in pre-trained language models (PLMs) have sparked considerable research focus and achieved promising performance on the approach of dense passage retrieval, which aims at retrieving relative passages from massive corpus with given questions. However, most of existing datasets mainly benchmark the models with factoid queries of general commonsense, while specialised fields such as finance and economics remain unexplored due to the deficiency of large-scale and high-quality datasets with expert annotations. In this work, we propose a new task, policy retrieval, by introducing the Chinese Stock Policy Retrieval Dataset (CSPRD), which provides 700+ prospectus passages labeled by experienced experts with relevant articles from 10k+ entries in our collected Chinese policy corpus. Experiments on lexical, embedding and fine-tuned bi-encoder models show the effectiveness of our proposed CSPRD yet also suggests ample potential for improvement. Our best performing baseline achieves 56.1% MRR@10, 28.5% NDCG@10, 37.5% Recall@10 and 80.6% Precision@10 on dev set.
PDF AbstractCode

Tasks

Datasets
Introduced in the Paper:
CSPRD