Cross-Model Comparative Loss for Enhancing Neuronal Utility in Language Understanding
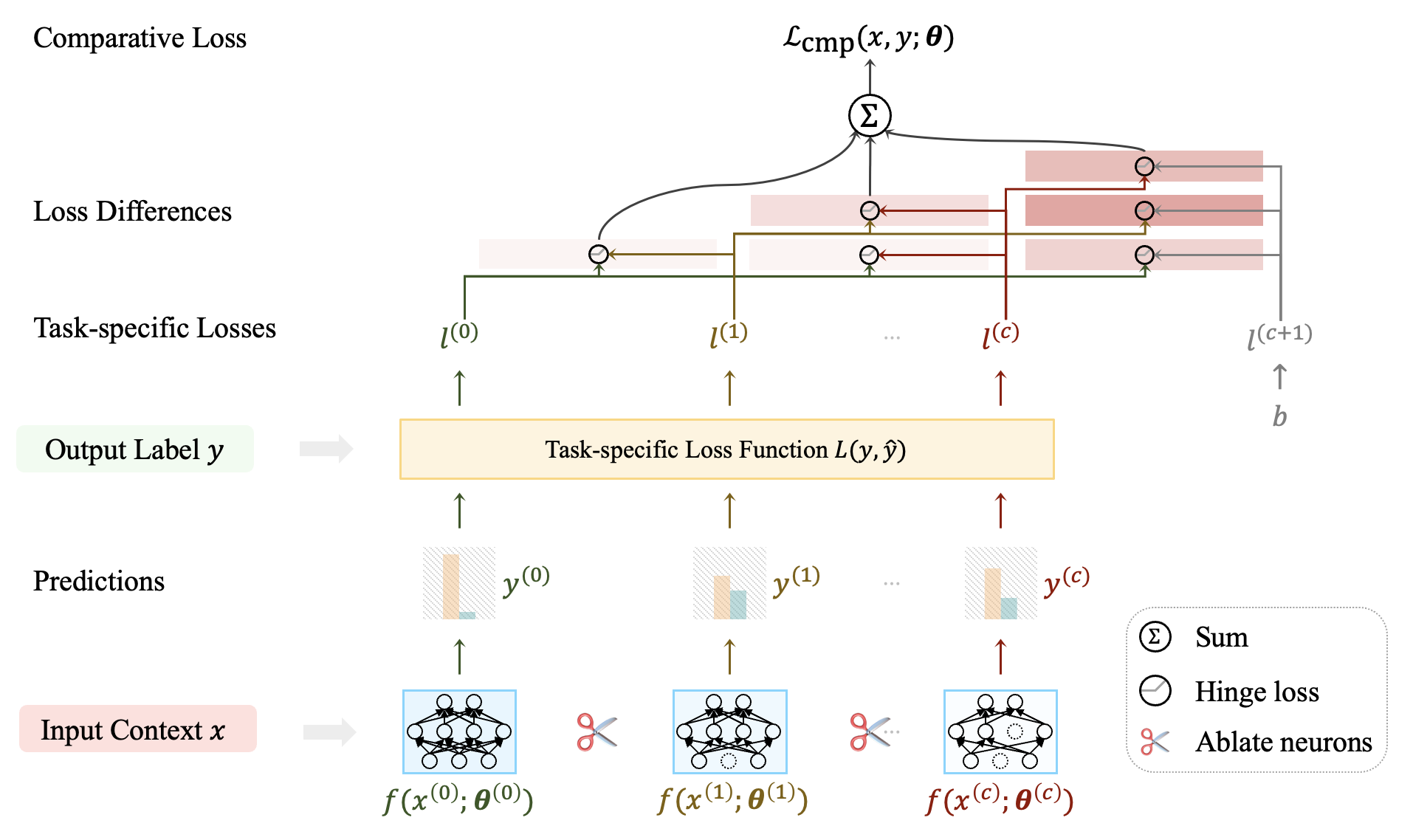
Current natural language understanding (NLU) models have been continuously scaling up, both in terms of model size and input context, introducing more hidden and input neurons. While this generally improves performance on average, the extra neurons do not yield a consistent improvement for all instances. This is because some hidden neurons are redundant, and the noise mixed in input neurons tends to distract the model. Previous work mainly focuses on extrinsically reducing low-utility neurons by additional post- or pre-processing, such as network pruning and context selection, to avoid this problem. Beyond that, can we make the model reduce redundant parameters and suppress input noise by intrinsically enhancing the utility of each neuron? If a model can efficiently utilize neurons, no matter which neurons are ablated (disabled), the ablated submodel should perform no better than the original full model. Based on such a comparison principle between models, we propose a cross-model comparative loss for a broad range of tasks. Comparative loss is essentially a ranking loss on top of the task-specific losses of the full and ablated models, with the expectation that the task-specific loss of the full model is minimal. We demonstrate the universal effectiveness of comparative loss through extensive experiments on 14 datasets from 3 distinct NLU tasks based on 5 widely used pretrained language models and find it particularly superior for models with few parameters or long input.
PDF Abstract

 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 MultiNLI
MultiNLI
 QNLI
QNLI
 MS MARCO
MS MARCO
 MRPC
MRPC
 CoLA
CoLA
 HotpotQA
HotpotQA
 DL-HARD
DL-HARD
