Cross-Modality Time-Variant Relation Learning for Generating Dynamic Scene Graphs
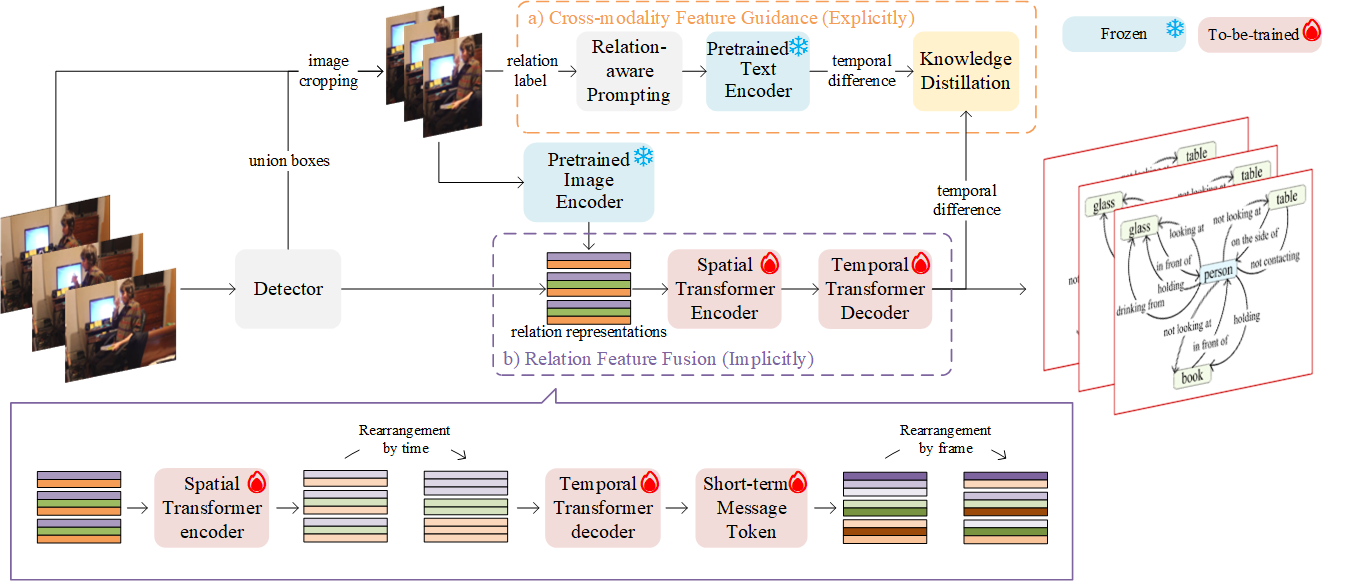
Dynamic scene graphs generated from video clips could help enhance the semantic visual understanding in a wide range of challenging tasks such as environmental perception, autonomous navigation, and task planning of self-driving vehicles and mobile robots. In the process of temporal and spatial modeling during dynamic scene graph generation, it is particularly intractable to learn time-variant relations in dynamic scene graphs among frames. In this paper, we propose a Time-variant Relation-aware TRansformer (TR$^2$), which aims to model the temporal change of relations in dynamic scene graphs. Explicitly, we leverage the difference of text embeddings of prompted sentences about relation labels as the supervision signal for relations. In this way, cross-modality feature guidance is realized for the learning of time-variant relations. Implicitly, we design a relation feature fusion module with a transformer and an additional message token that describes the difference between adjacent frames. Extensive experiments on the Action Genome dataset prove that our TR$^2$ can effectively model the time-variant relations. TR$^2$ significantly outperforms previous state-of-the-art methods under two different settings by 2.1% and 2.6% respectively.
PDF Abstract

