CriticBench: Evaluating Large Language Models as Critic
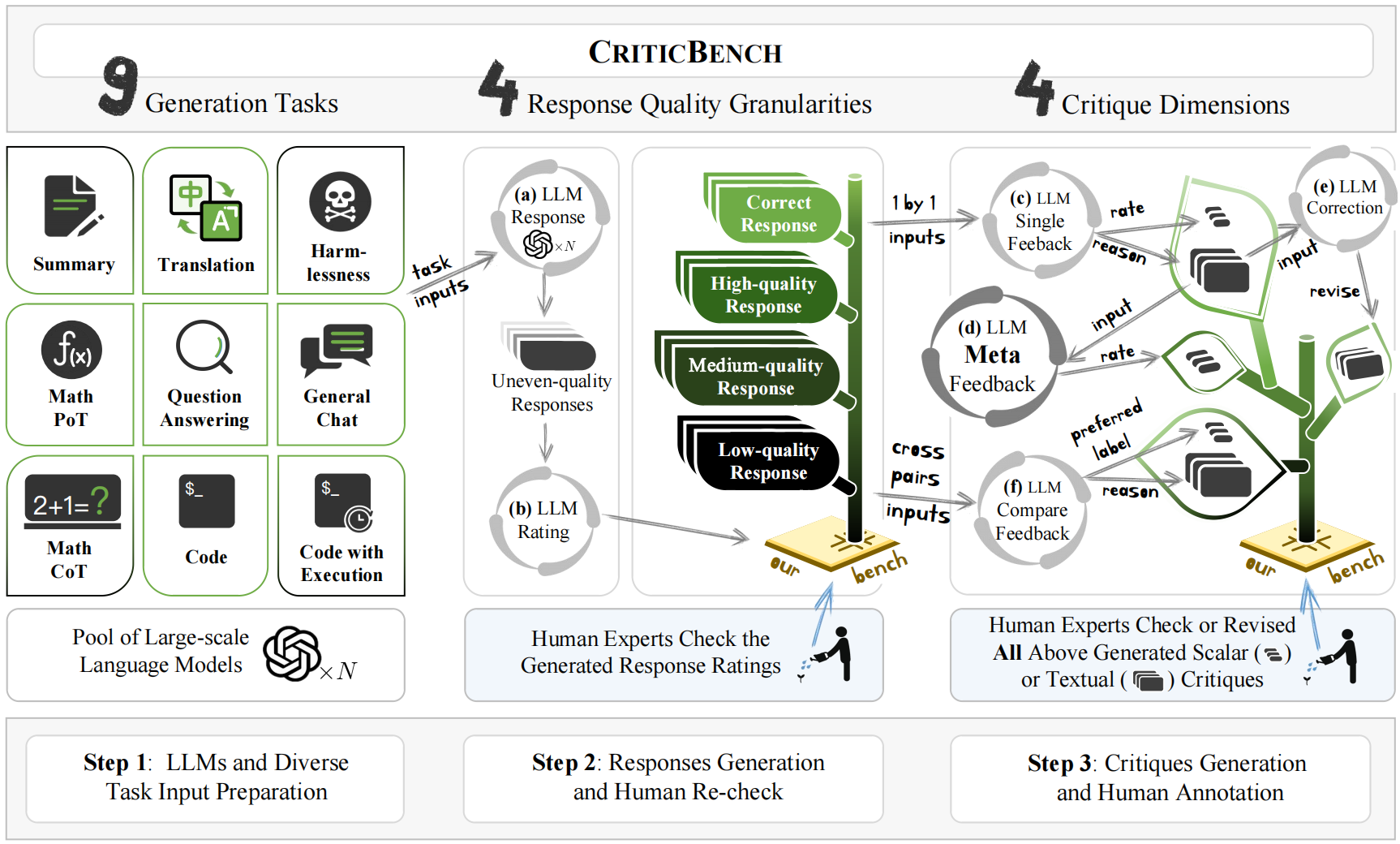
Critique ability are crucial in the scalable oversight and self-improvement of Large Language Models (LLMs). While many recent studies explore the critique ability of LLMs to judge and refine flaws in generations, how to comprehensively and reliably measure the critique abilities of LLMs is under-explored. This paper introduces CriticBench, a novel benchmark designed to comprehensively and reliably evaluate four key critique ability dimensions of LLMs: feedback, comparison, refinement and meta-feedback. CriticBench encompasses nine diverse tasks, each assessing the LLMs' ability to critique responses at varying levels of quality granularity. Our extensive evaluations of open-source and closed-source LLMs reveal intriguing relationships between the critique ability and tasks, response qualities, and model scales. Datasets, resources and evaluation toolkit for CriticBench will be publicly released at https://github.com/open-compass/CriticBench.
PDF AbstractTasks
Datasets
Introduced in the Paper:
open-compass/CriticBench