Controlling Vision-Language Models for Multi-Task Image Restoration
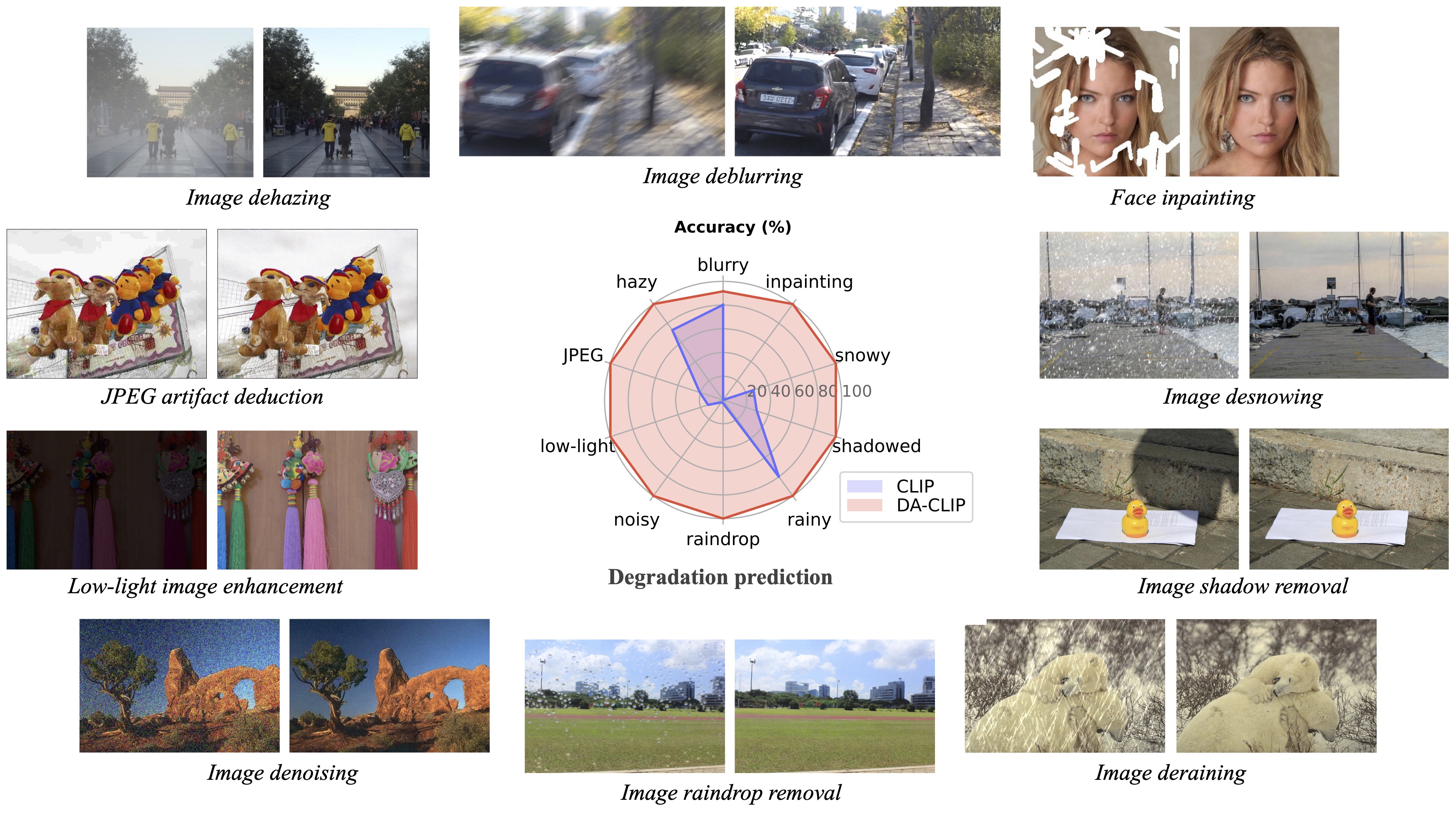
Vision-language models such as CLIP have shown great impact on diverse downstream tasks for zero-shot or label-free predictions. However, when it comes to low-level vision such as image restoration their performance deteriorates dramatically due to corrupted inputs. In this paper, we present a degradation-aware vision-language model (DA-CLIP) to better transfer pretrained vision-language models to low-level vision tasks as a multi-task framework for image restoration. More specifically, DA-CLIP trains an additional controller that adapts the fixed CLIP image encoder to predict high-quality feature embeddings. By integrating the embedding into an image restoration network via cross-attention, we are able to pilot the model to learn a high-fidelity image reconstruction. The controller itself will also output a degradation feature that matches the real corruptions of the input, yielding a natural classifier for different degradation types. In addition, we construct a mixed degradation dataset with synthetic captions for DA-CLIP training. Our approach advances state-of-the-art performance on both \emph{degradation-specific} and \emph{unified} image restoration tasks, showing a promising direction of prompting image restoration with large-scale pretrained vision-language models. Our code is available at https://github.com/Algolzw/daclip-uir.
PDF Abstract Colab
Colab
 Spaces
Spaces
 Replicate
Replicate







 GoPro
GoPro
 LOL
LOL
 Raindrop
Raindrop
 Synthetic Rain Datasets
Synthetic Rain Datasets

