Contrastive Positive Sample Propagation along the Audio-Visual Event Line
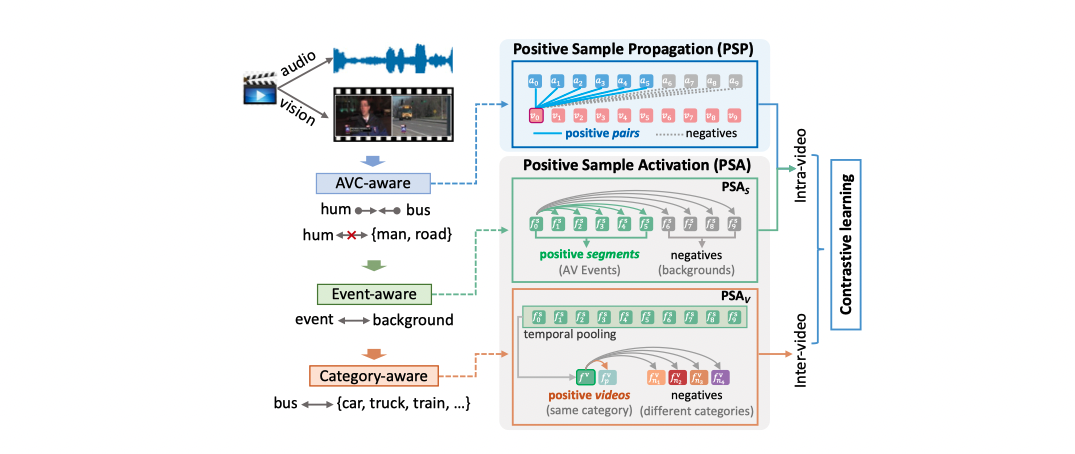
Visual and audio signals often coexist in natural environments, forming audio-visual events (AVEs). Given a video, we aim to localize video segments containing an AVE and identify its category. It is pivotal to learn the discriminative features for each video segment. Unlike existing work focusing on audio-visual feature fusion, in this paper, we propose a new contrastive positive sample propagation (CPSP) method for better deep feature representation learning. The contribution of CPSP is to introduce the available full or weak label as a prior that constructs the exact positive-negative samples for contrastive learning. Specifically, the CPSP involves comprehensive contrastive constraints: pair-level positive sample propagation (PSP), segment-level and video-level positive sample activation (PSA$_S$ and PSA$_V$). Three new contrastive objectives are proposed (\emph{i.e.}, $\mathcal{L}_{\text{avpsp}}$, $\mathcal{L}_\text{spsa}$, and $\mathcal{L}_\text{vpsa}$) and introduced into both the fully and weakly supervised AVE localization. To draw a complete picture of the contrastive learning in AVE localization, we also study the self-supervised positive sample propagation (SSPSP). As a result, CPSP is more helpful to obtain the refined audio-visual features that are distinguishable from the negatives, thus benefiting the classifier prediction. Extensive experiments on the AVE and the newly collected VGGSound-AVEL100k datasets verify the effectiveness and generalization ability of our method.
PDF Abstract


 VGG-Sound
VGG-Sound
