Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation
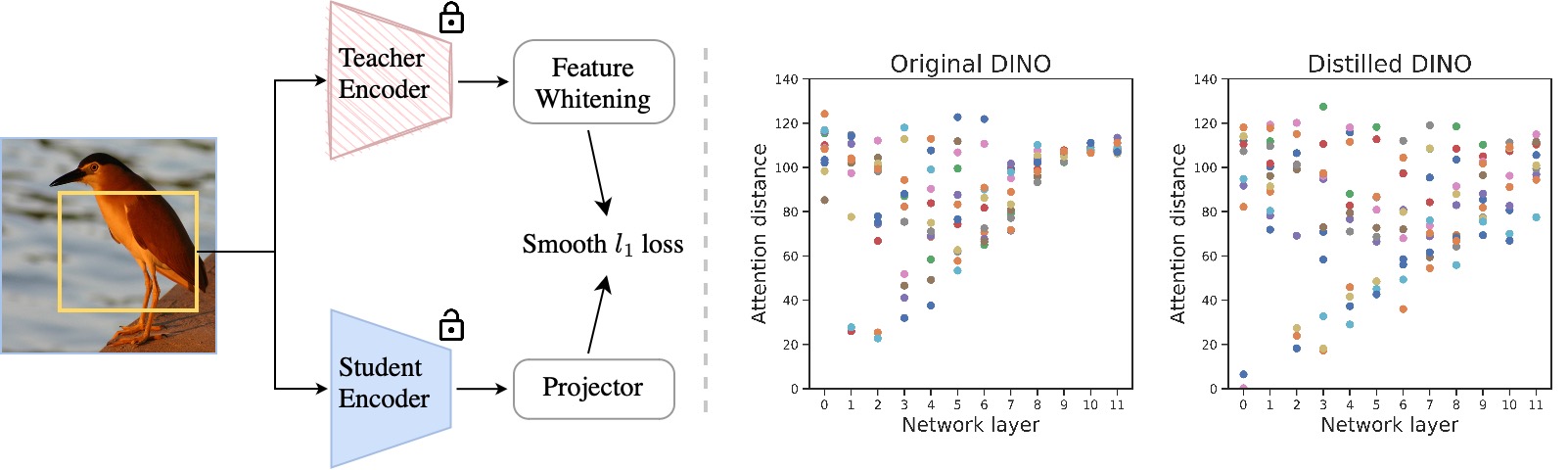
Masked image modeling (MIM) learns representations with remarkably good fine-tuning performances, overshadowing previous prevalent pre-training approaches such as image classification, instance contrastive learning, and image-text alignment. In this paper, we show that the inferior fine-tuning performance of these pre-training approaches can be significantly improved by a simple post-processing in the form of feature distillation (FD). The feature distillation converts the old representations to new representations that have a few desirable properties just like those representations produced by MIM. These properties, which we aggregately refer to as optimization friendliness, are identified and analyzed by a set of attention- and optimization-related diagnosis tools. With these properties, the new representations show strong fine-tuning performance. Specifically, the contrastive self-supervised learning methods are made as competitive in fine-tuning as the state-of-the-art masked image modeling (MIM) algorithms. The CLIP models' fine-tuning performance is also significantly improved, with a CLIP ViT-L model reaching 89.0% top-1 accuracy on ImageNet-1K classification. On the 3-billion-parameter SwinV2-G model, the fine-tuning accuracy is improved by +1.5 mIoU / +1.1 mAP to 61.4 mIoU / 64.2 mAP on ADE20K semantic segmentation and COCO object detection, respectively, creating new records on both benchmarks. More importantly, our work provides a way for the future research to focus more effort on the generality and scalability of the learnt representations without being pre-occupied with optimization friendliness since it can be enhanced rather easily. The code will be available at https://github.com/SwinTransformer/Feature-Distillation.
PDF Abstract







 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
Results from the Paper
 Ranked #2 on
Instance Segmentation
on COCO test-dev
(using extra training data)
Ranked #2 on
Instance Segmentation
on COCO test-dev
(using extra training data)
