A unified model for continuous conditional video prediction
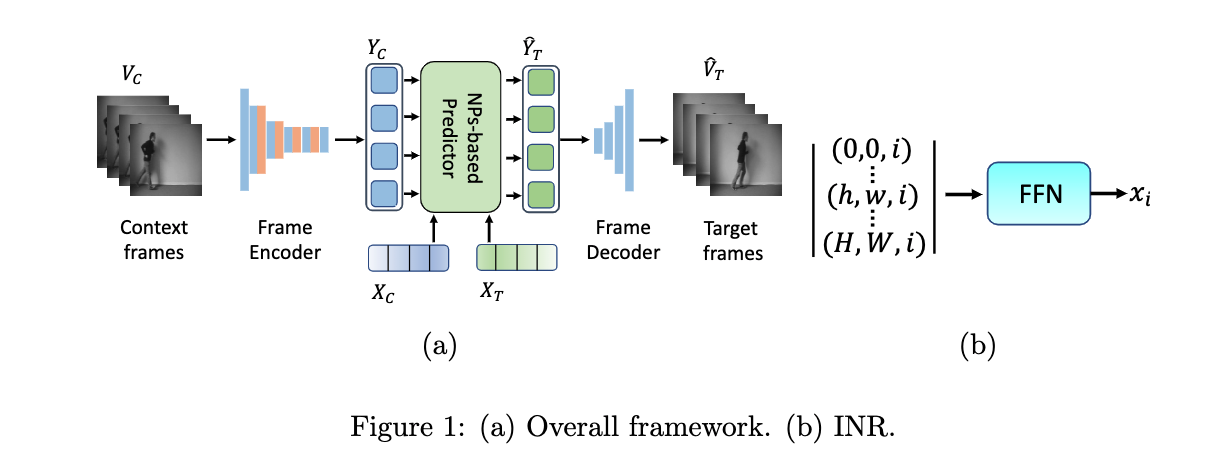
Different conditional video prediction tasks, like video future frame prediction and video frame interpolation, are normally solved by task-related models even though they share many common underlying characteristics. Furthermore, almost all conditional video prediction models can only achieve discrete prediction. In this paper, we propose a unified model that addresses these two issues at the same time. We show that conditional video prediction can be formulated as a neural process, which maps input spatio-temporal coordinates to target pixel values given context spatio-temporal coordinates and context pixel values. Specifically, we feed the implicit neural representation of coordinates and context pixel features into a Transformer-based non-autoregressive conditional video prediction model. Our task-specific models outperform previous work for video future frame prediction and video interpolation on multiple datasets. Importantly, the model is able to interpolate or predict with an arbitrary high frame rate, i.e., continuous prediction. Our source code is available at \url{https://npvp.github.io}.
PDF Abstract


 Cityscapes
Cityscapes
 KITTI
KITTI
 KTH
KTH
