Consolidator: Mergeable Adapter with Grouped Connections for Visual Adaptation
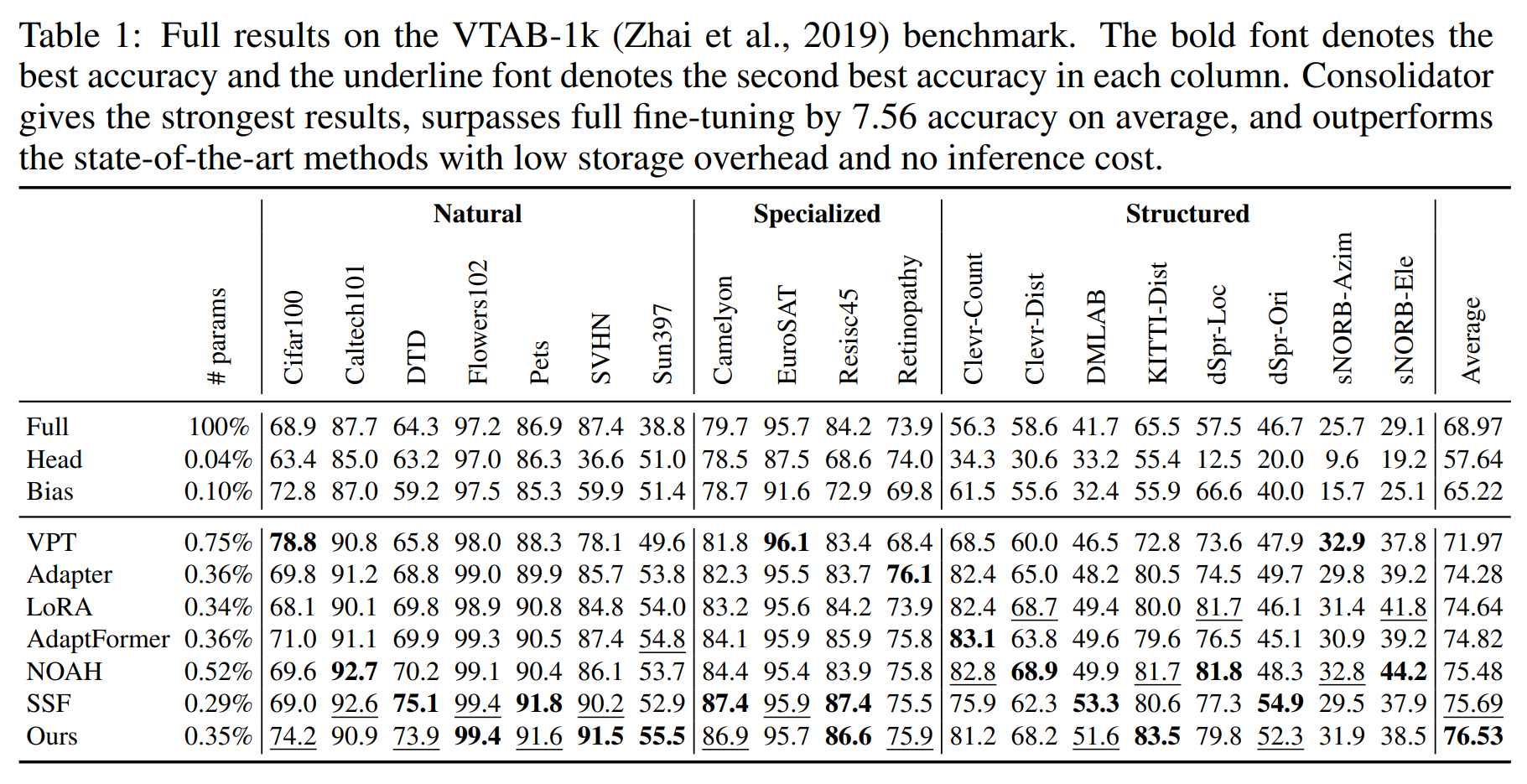
Recently, transformers have shown strong ability as visual feature extractors, surpassing traditional convolution-based models in various scenarios. However, the success of vision transformers largely owes to their capacity to accommodate numerous parameters. As a result, new challenges for adapting large models to downstream tasks arise. On the one hand, classic fine-tuning tunes all parameters in a huge model for every task and thus easily falls into overfitting, leading to inferior performance. On the other hand, on resource-limited devices, fine-tuning stores a full copy of parameters and thus is usually impracticable for the shortage of storage space. However, few works have focused on how to efficiently and effectively transfer knowledge in a vision transformer. Existing methods did not dive into the properties of visual features, leading to inferior performance. Moreover, some of them bring heavy inference cost though benefiting storage. To tackle these problems, we propose consolidator to modify the pre-trained model with the addition of a small set of tunable parameters to temporarily store the task-specific knowledge while freezing the backbone model. Motivated by the success of group-wise convolution, we adopt grouped connections across the features extracted by fully connected layers to construct tunable parts in a consolidator. To further enhance the model's capacity to transfer knowledge under a constrained storage budget and keep inference efficient, we consolidate the parameters in two stages: 1. between adaptation and storage, and 2. between loading and inference. On a series of downstream visual tasks, our consolidator can reach up to 7.56 better accuracy than full fine-tuning with merely 0.35% parameters, and outperform state-of-the-art parameter-efficient tuning methods by a clear margin. Code is available at https://github.com/beyondhtx/Consolidator.
PDF Abstract
 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 CUB-200-2011
CUB-200-2011
 Oxford 102 Flower
Oxford 102 Flower
 DTD
DTD
 Caltech-101
Caltech-101
 EuroSAT
EuroSAT
