ConDA: Contrastive Domain Adaptation for AI-generated Text Detection
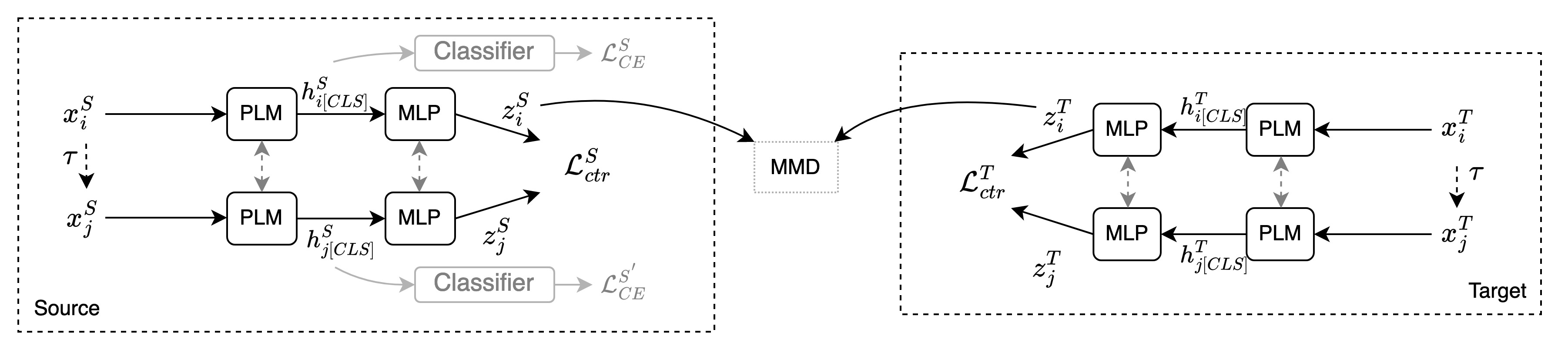
Large language models (LLMs) are increasingly being used for generating text in a variety of use cases, including journalistic news articles. Given the potential malicious nature in which these LLMs can be used to generate disinformation at scale, it is important to build effective detectors for such AI-generated text. Given the surge in development of new LLMs, acquiring labeled training data for supervised detectors is a bottleneck. However, there might be plenty of unlabeled text data available, without information on which generator it came from. In this work we tackle this data problem, in detecting AI-generated news text, and frame the problem as an unsupervised domain adaptation task. Here the domains are the different text generators, i.e. LLMs, and we assume we have access to only the labeled source data and unlabeled target data. We develop a Contrastive Domain Adaptation framework, called ConDA, that blends standard domain adaptation techniques with the representation power of contrastive learning to learn domain invariant representations that are effective for the final unsupervised detection task. Our experiments demonstrate the effectiveness of our framework, resulting in average performance gains of 31.7% from the best performing baselines, and within 0.8% margin of a fully supervised detector. All our code and data is available at https://github.com/AmritaBh/ConDA-gen-text-detection.
PDF Abstract



 WebText
WebText
