Compressed Context Memory For Online Language Model Interaction
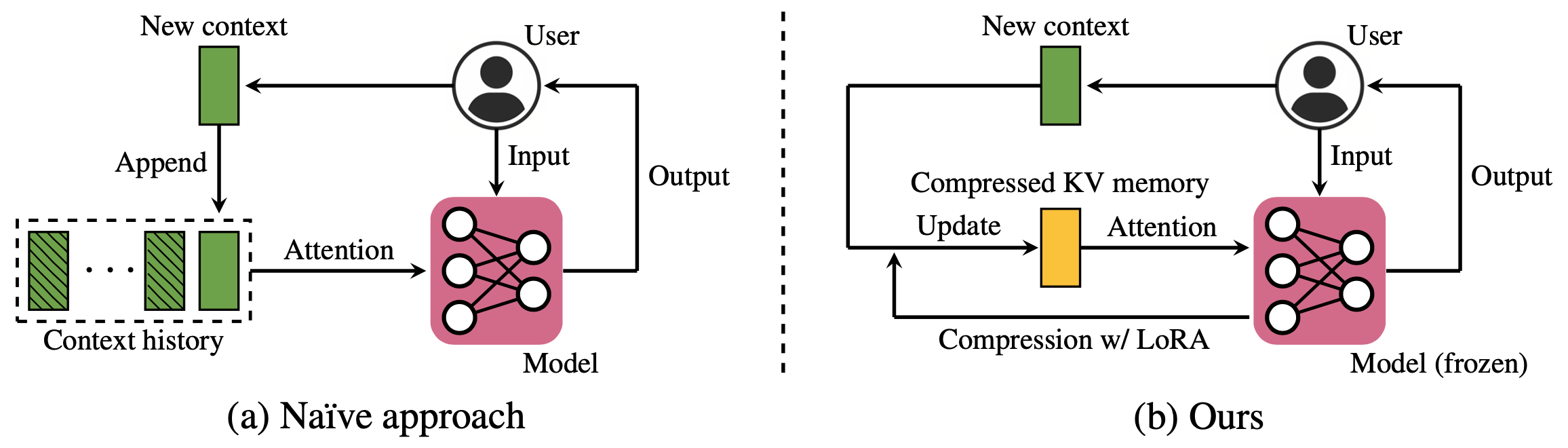
This paper presents a context key/value compression method for Transformer language models in online scenarios, where the context continually expands. As the context lengthens, the attention process demands increasing memory and computations, which in turn reduces the throughput of the language model. To address this challenge, we propose a compressed context memory system that continually compresses the accumulating attention key/value pairs into a compact memory space, facilitating language model inference in a limited memory space of computing environments. Our compression process involves integrating a lightweight conditional LoRA into the language model's forward pass during inference, without the need for fine-tuning the model's entire set of weights. We achieve efficient training by modeling the recursive compression process as a single parallelized forward computation. Through evaluations on conversation, personalization, and multi-task learning, we demonstrate that our approach achieves the performance level of a full context model with $5\times$ smaller context memory size. We further demonstrate the applicability of our approach in a streaming setting with an unlimited context length, outperforming the sliding window approach. Codes are available at https://github.com/snu-mllab/context-memory.
PDF Abstract


 DailyDialog
DailyDialog
 SODA
SODA
