Composing General Audio Representation by Fusing Multilayer Features of a Pre-trained Model
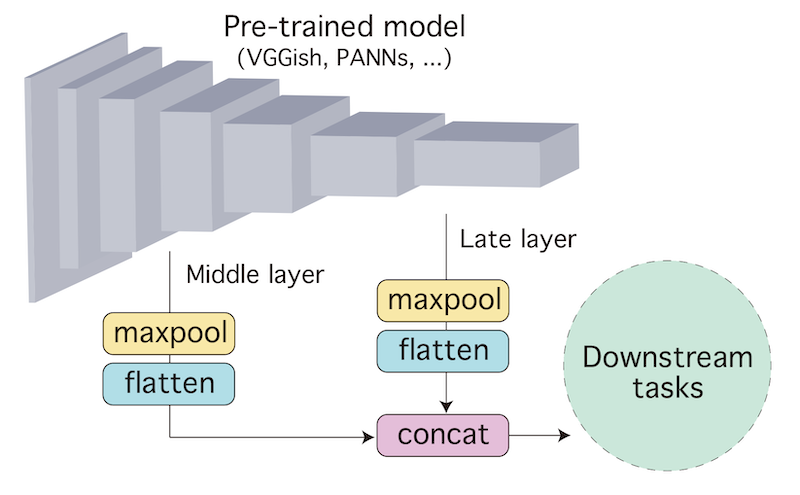
Many application studies rely on audio DNN models pre-trained on a large-scale dataset as essential feature extractors, and they extract features from the last layers. In this study, we focus on our finding that the middle layer features of existing supervised pre-trained models are more effective than the late layer features for some tasks. We propose a simple approach to compose features effective for general-purpose applications, consisting of two steps: (1) calculating feature vectors along the time frame from middle/late layer outputs, and (2) fusing them. This approach improves the utility of frequency and channel information in downstream processes, and combines the effectiveness of middle and late layer features for different tasks. As a result, the feature vectors become effective for general purposes. In the experiments using VGGish, PANNs' CNN14, and AST on nine downstream tasks, we first show that each layer output of these models serves different tasks. Then, we demonstrate that the proposed approach significantly improves their performance and brings it to a level comparable to that of the state-of-the-art. In particular, the performance of the non-semantic speech (NOSS) tasks greatly improves, especially on Speech commands V2 with VGGish of +77.1 (14.3% to 91.4%).
PDF Abstract
 AudioSet
AudioSet
 Speech Commands
Speech Commands
 ESC-50
ESC-50
 UrbanSound8K
UrbanSound8K
 NSynth
NSynth
