CompanyKG: A Large-Scale Heterogeneous Graph for Company Similarity Quantification
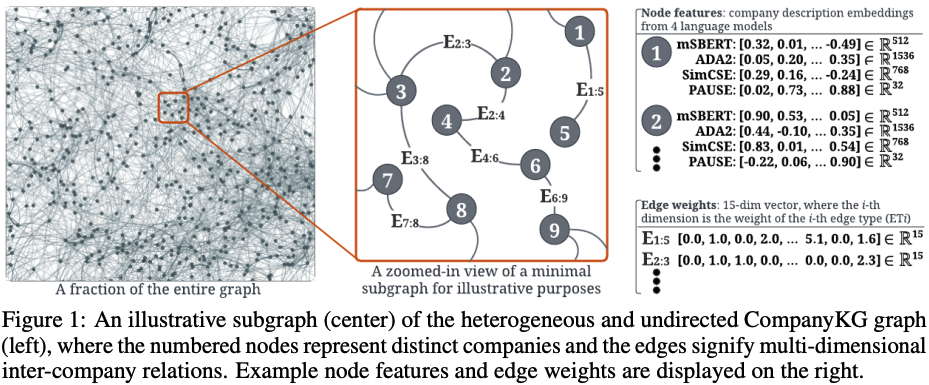
In the investment industry, it is often essential to carry out fine-grained company similarity quantification for a range of purposes, including market mapping, competitor analysis, and mergers and acquisitions. We propose and publish a knowledge graph, named CompanyKG, to represent and learn diverse company features and relations. Specifically, 1.17 million companies are represented as nodes enriched with company description embeddings; and 15 different inter-company relations result in 51.06 million weighted edges. To enable a comprehensive assessment of methods for company similarity quantification, we have devised and compiled three evaluation tasks with annotated test sets: similarity prediction, competitor retrieval and similarity ranking. We present extensive benchmarking results for 11 reproducible predictive methods categorized into three groups: node-only, edge-only, and node+edge. To the best of our knowledge, CompanyKG is the first large-scale heterogeneous graph dataset originating from a real-world investment platform, tailored for quantifying inter-company similarity.
PDF Abstract

