Communication-Computation Trade-Off in Resource-Constrained Edge Inference
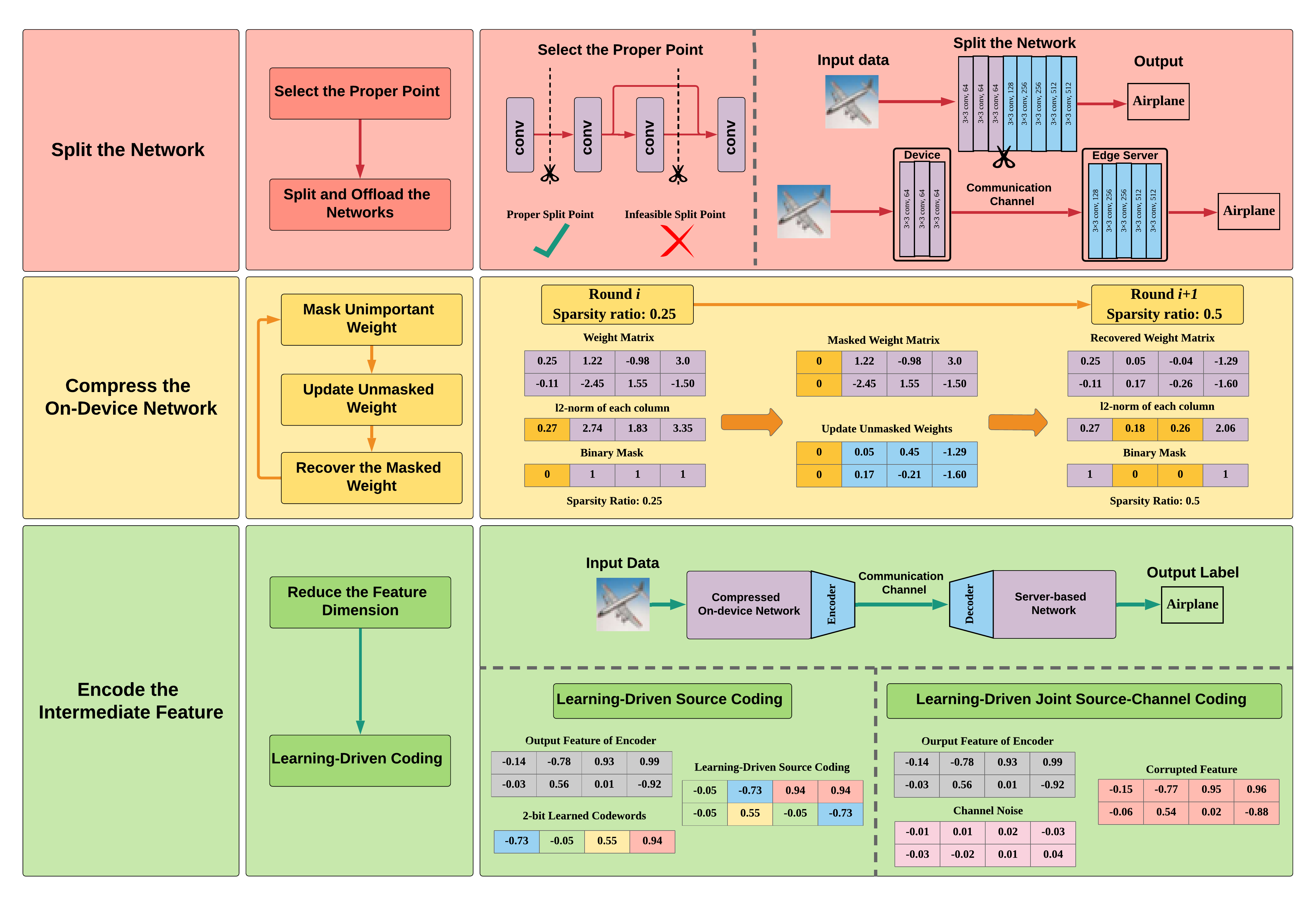
The recent breakthrough in artificial intelligence (AI), especially deep neural networks (DNNs), has affected every branch of science and technology. Particularly, edge AI has been envisioned as a major application scenario to provide DNN-based services at edge devices. This article presents effective methods for edge inference at resource-constrained devices. It focuses on device-edge co-inference, assisted by an edge computing server, and investigates a critical trade-off among the computation cost of the on-device model and the communication cost of forwarding the intermediate feature to the edge server. A three-step framework is proposed for the effective inference: (1) model split point selection to determine the on-device model, (2) communication-aware model compression to reduce the on-device computation and the resulting communication overhead simultaneously, and (3) task-oriented encoding of the intermediate feature to further reduce the communication overhead. Experiments demonstrate that our proposed framework achieves a better trade-off and significantly reduces the inference latency than baseline methods.
PDF Abstract

