CoMAE: Single Model Hybrid Pre-training on Small-Scale RGB-D Datasets
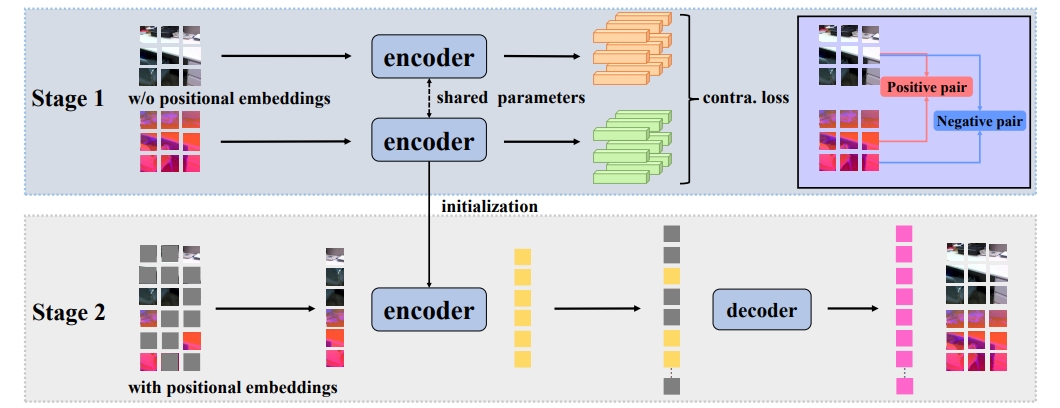
Current RGB-D scene recognition approaches often train two standalone backbones for RGB and depth modalities with the same Places or ImageNet pre-training. However, the pre-trained depth network is still biased by RGB-based models which may result in a suboptimal solution. In this paper, we present a single-model self-supervised hybrid pre-training framework for RGB and depth modalities, termed as CoMAE. Our CoMAE presents a curriculum learning strategy to unify the two popular self-supervised representation learning algorithms: contrastive learning and masked image modeling. Specifically, we first build a patch-level alignment task to pre-train a single encoder shared by two modalities via cross-modal contrastive learning. Then, the pre-trained contrastive encoder is passed to a multi-modal masked autoencoder to capture the finer context features from a generative perspective. In addition, our single-model design without requirement of fusion module is very flexible and robust to generalize to unimodal scenario in both training and testing phases. Extensive experiments on SUN RGB-D and NYUDv2 datasets demonstrate the effectiveness of our CoMAE for RGB and depth representation learning. In addition, our experiment results reveal that CoMAE is a data-efficient representation learner. Although we only use the small-scale and unlabeled training set for pre-training, our CoMAE pre-trained models are still competitive to the state-of-the-art methods with extra large-scale and supervised RGB dataset pre-training. Code will be released at https://github.com/MCG-NJU/CoMAE.
PDF Abstract



 ImageNet
ImageNet
 NYUv2
NYUv2
 Places205
Places205
