CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
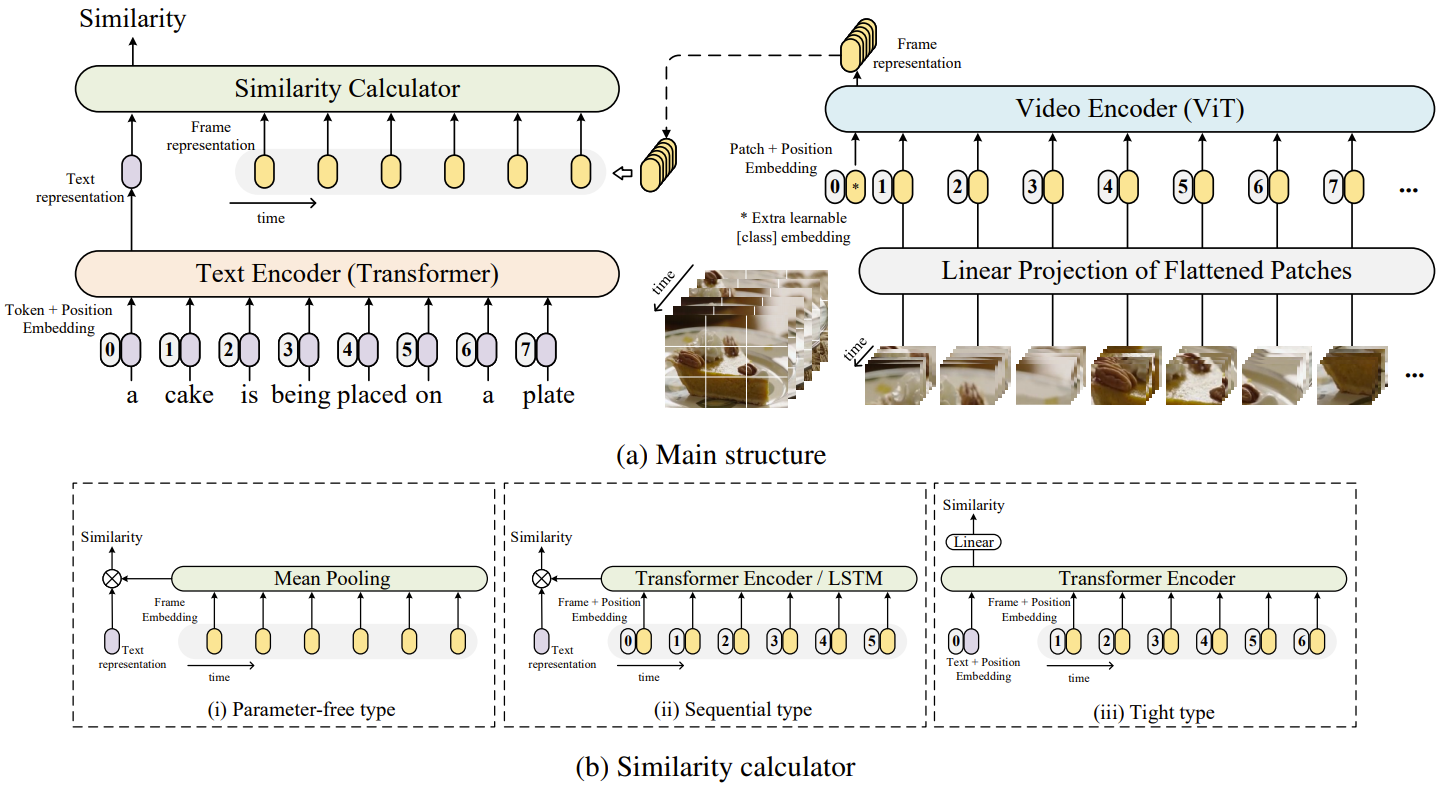
Video-text retrieval plays an essential role in multi-modal research and has been widely used in many real-world web applications. The CLIP (Contrastive Language-Image Pre-training), an image-language pre-training model, has demonstrated the power of visual concepts learning from web collected image-text datasets. In this paper, we propose a CLIP4Clip model to transfer the knowledge of the CLIP model to video-language retrieval in an end-to-end manner. Several questions are investigated via empirical studies: 1) Whether image feature is enough for video-text retrieval? 2) How a post-pretraining on a large-scale video-text dataset based on the CLIP affect the performance? 3) What is the practical mechanism to model temporal dependency between video frames? And 4) The Hyper-parameters sensitivity of the model on video-text retrieval task. Extensive experimental results present that the CLIP4Clip model transferred from the CLIP can achieve SOTA results on various video-text retrieval datasets, including MSR-VTT, MSVC, LSMDC, ActivityNet, and DiDeMo. We release our code at https://github.com/ArrowLuo/CLIP4Clip.
PDF Abstract

 Visual Genome
Visual Genome
 ActivityNet
ActivityNet
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 HowTo100M
HowTo100M
 DiDeMo
DiDeMo
 COCO Captions
COCO Captions
 WebVid
WebVid
 LSMDC
LSMDC

