CLIP-VQDiffusion : Langauge Free Training of Text To Image generation using CLIP and vector quantized diffusion model
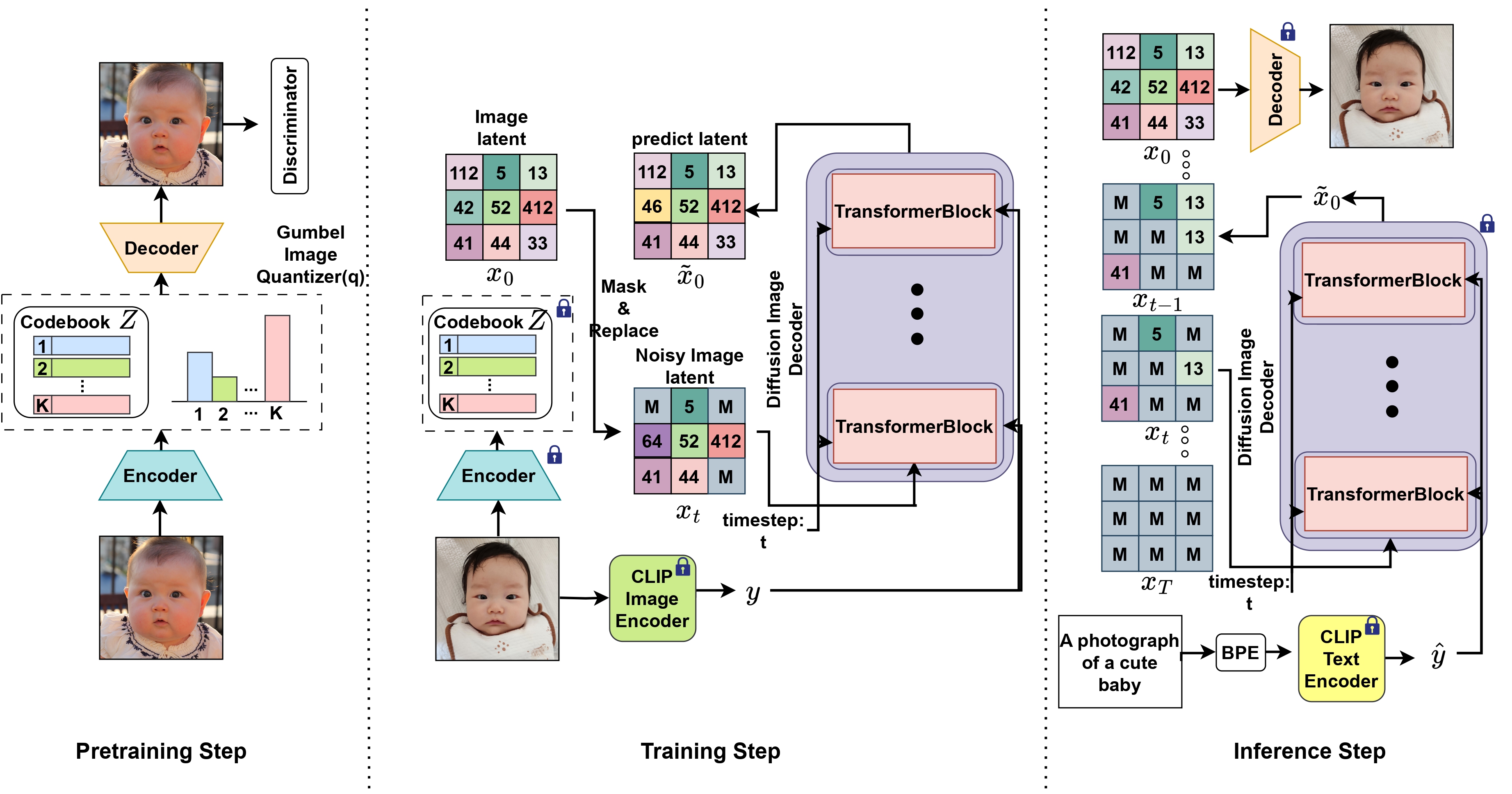
There has been a significant progress in text conditional image generation models. Recent advancements in this field depend not only on improvements in model structures, but also vast quantities of text-image paired datasets. However, creating these kinds of datasets is very costly and requires a substantial amount of labor. Famous face datasets don't have corresponding text captions, making it difficult to develop text conditional image generation models on these datasets. Some research has focused on developing text to image generation models using only images without text captions. Here, we propose CLIP-VQDiffusion, which leverage the pretrained CLIP model to provide multimodal text-image representations and strong image generation capabilities. On the FFHQ dataset, our model outperformed previous state-of-the-art methods by 4.4% in clipscore and generated very realistic images even when the text was both in and out of distribution. The pretrained models and codes will soon be available at https://github.com/INFINIQ-AI1/CLIPVQDiffusion
PDF Abstract



 MS COCO
MS COCO
 FFHQ
FFHQ
