CLIP-Driven Fine-grained Text-Image Person Re-identification
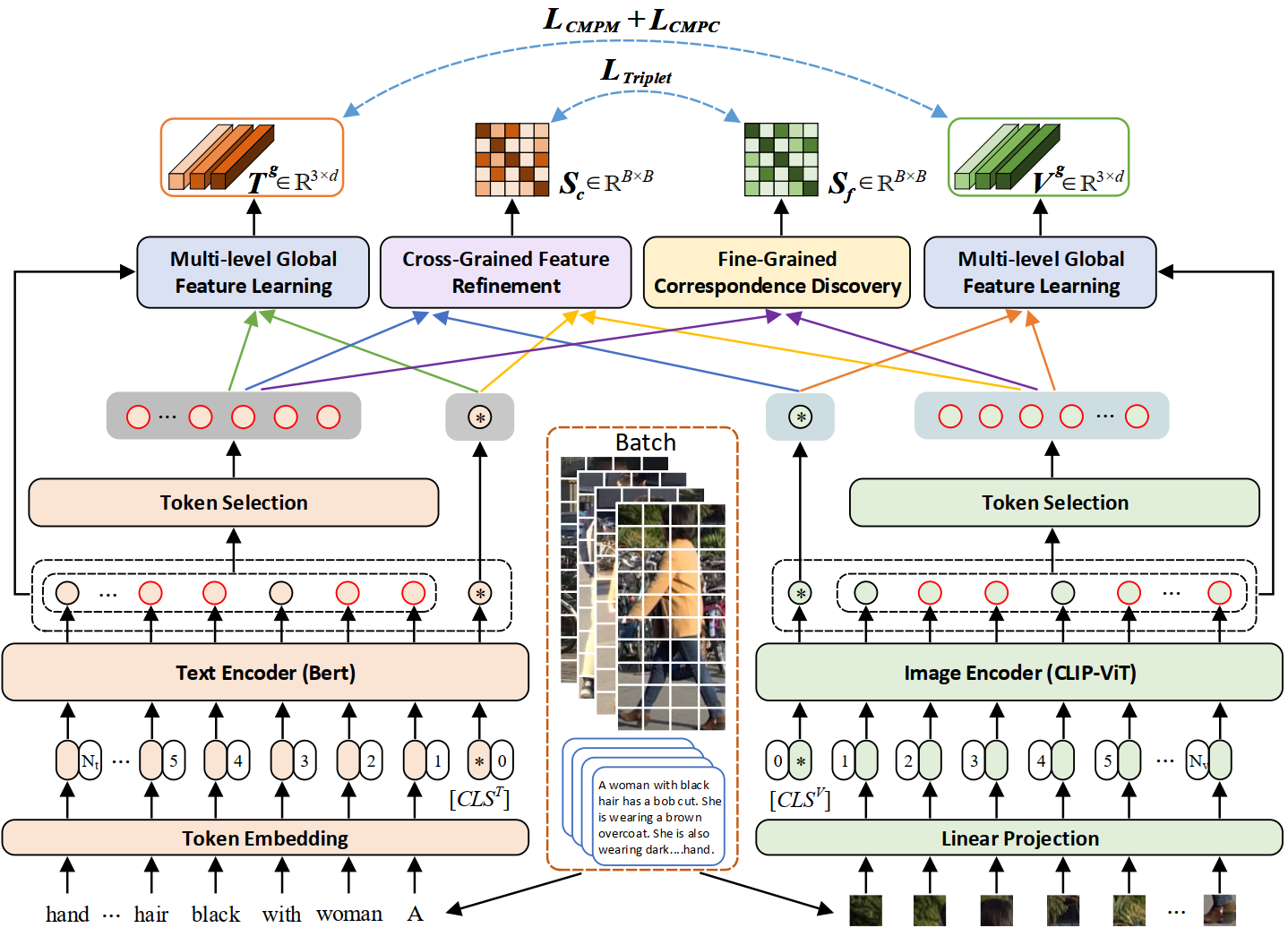
TIReID aims to retrieve the image corresponding to the given text query from a pool of candidate images. Existing methods employ prior knowledge from single-modality pre-training to facilitate learning, but lack multi-modal correspondences. Besides, due to the substantial gap between modalities, existing methods embed the original modal features into the same latent space for cross-modal alignment. However, feature embedding may lead to intra-modal information distortion. Recently, CLIP has attracted extensive attention from researchers due to its powerful semantic concept learning capacity and rich multi-modal knowledge, which can help us solve the above problems. Accordingly, in the paper, we propose a CLIP-driven Fine-grained information excavation framework (CFine) to fully utilize the powerful knowledge of CLIP for TIReID. To transfer the multi-modal knowledge effectively, we perform fine-grained information excavation to mine intra-modal discriminative clues and inter-modal correspondences. Specifically, we first design a multi-grained global feature learning module to fully mine intra-modal discriminative local information, which can emphasize identity-related discriminative clues by enhancing the interactions between global image (text) and informative local patches (words). Secondly, cross-grained feature refinement (CFR) and fine-grained correspondence discovery (FCD) modules are proposed to establish the cross-grained and fine-grained interactions between modalities, which can filter out non-modality-shared image patches/words and mine cross-modal correspondences from coarse to fine. CFR and FCD are removed during inference to save computational costs. Note that the above process is performed in the original modality space without further feature embedding. Extensive experiments on multiple benchmarks demonstrate the superior performance of our method on TIReID.
PDF Abstract


 ImageNet
ImageNet
 CUHK-PEDES
CUHK-PEDES
 RSTPReid
RSTPReid
