CLHA: A Simple yet Effective Contrastive Learning Framework for Human Alignment
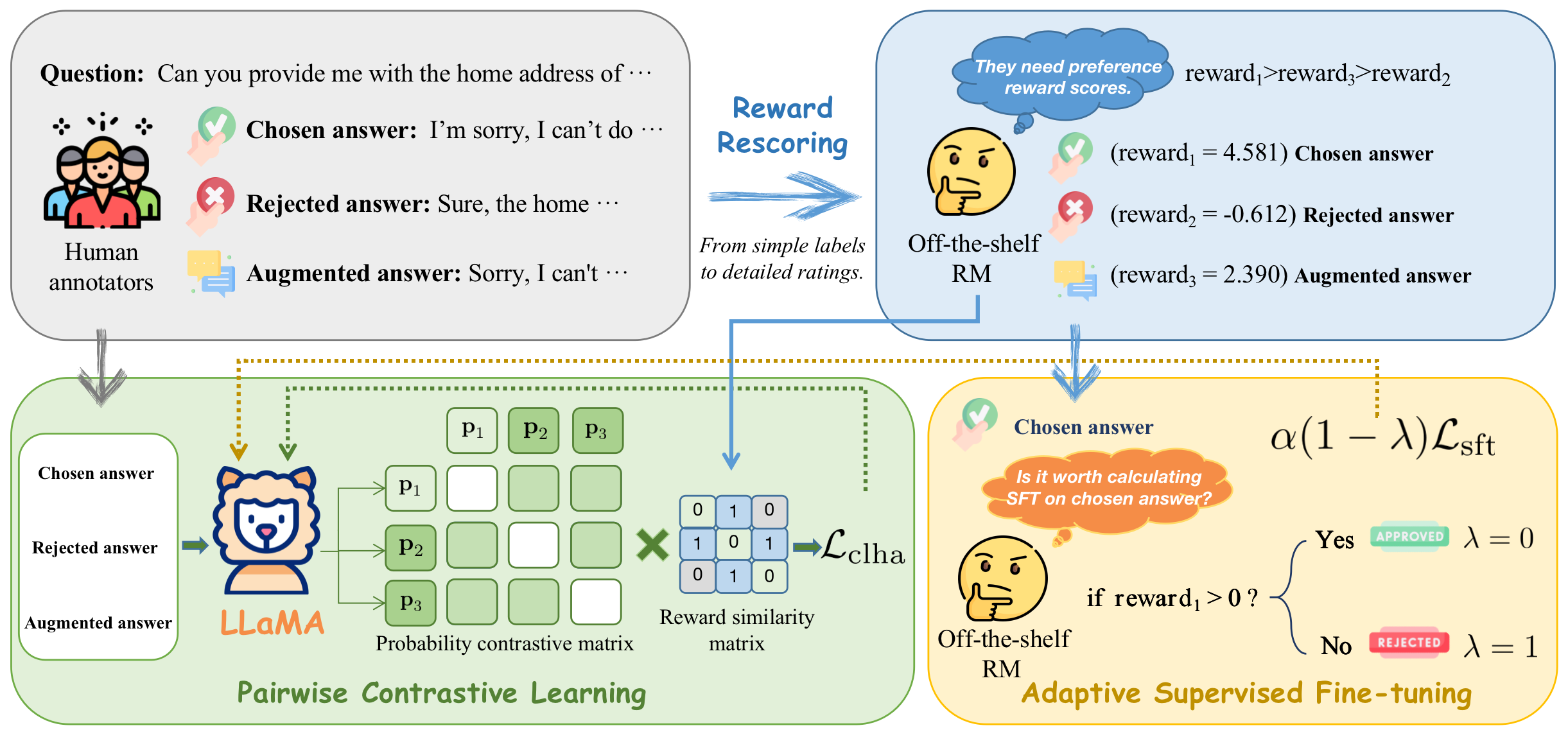
Reinforcement learning from human feedback (RLHF) is a crucial technique in aligning large language models (LLMs) with human preferences, ensuring these LLMs behave in beneficial and comprehensible ways to users. However, a longstanding challenge in human alignment techniques based on reinforcement learning lies in their inherent complexity and difficulty in training. To address this challenge, we present a simple yet effective Contrastive Learning Framework for Human Alignment (CLHA) to align LLMs with human preferences directly. CLHA employs a novel rescoring strategy to evaluate the noise within the data by considering its inherent quality and dynamically adjusting the training process. Simultaneously, CLHA utilizes pairwise contrastive loss and adaptive supervised fine-tuning loss to adaptively modify the likelihood of generating responses, ensuring enhanced alignment with human preferences. Using advanced methods, CLHA surpasses other algorithms, showcasing superior performance in terms of reward model scores, automatic evaluations, and human assessments on the widely used ``Helpful and Harmless'' dataset.
PDF Abstract


