Dual Modality Prompt Tuning for Vision-Language Pre-Trained Model
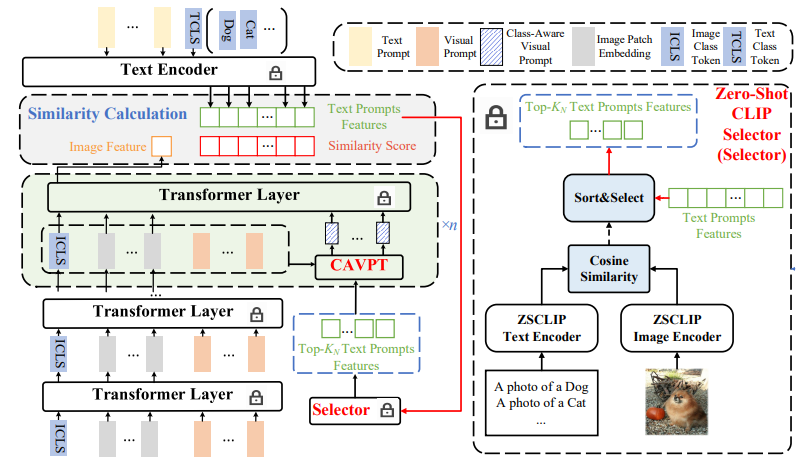
With the emergence of large pre-trained vison-language model like CLIP, transferable representations can be adapted to a wide range of downstream tasks via prompt tuning. Prompt tuning tries to probe the beneficial information for downstream tasks from the general knowledge stored in the pre-trained model. A recently proposed method named Context Optimization (CoOp) introduces a set of learnable vectors as text prompt from the language side. However, tuning the text prompt alone can only adjust the synthesized "classifier", while the computed visual features of the image encoder can not be affected , thus leading to sub-optimal solutions. In this paper, we propose a novel Dual-modality Prompt Tuning (DPT) paradigm through learning text and visual prompts simultaneously. To make the final image feature concentrate more on the target visual concept, a Class-Aware Visual Prompt Tuning (CAVPT) scheme is further proposed in our DPT, where the class-aware visual prompt is generated dynamically by performing the cross attention between text prompts features and image patch token embeddings to encode both the downstream task-related information and visual instance information. Extensive experimental results on 11 datasets demonstrate the effectiveness and generalization ability of the proposed method. Our code is available in https://github.com/fanrena/DPT.
PDF Abstract


 ImageNet
ImageNet
 UCF101
UCF101
 Oxford 102 Flower
Oxford 102 Flower
 Stanford Cars
Stanford Cars
 DTD
DTD
 Food-101
Food-101
 Caltech-101
Caltech-101
 EuroSAT
EuroSAT
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
 ImageNet-Sketch
ImageNet-Sketch
