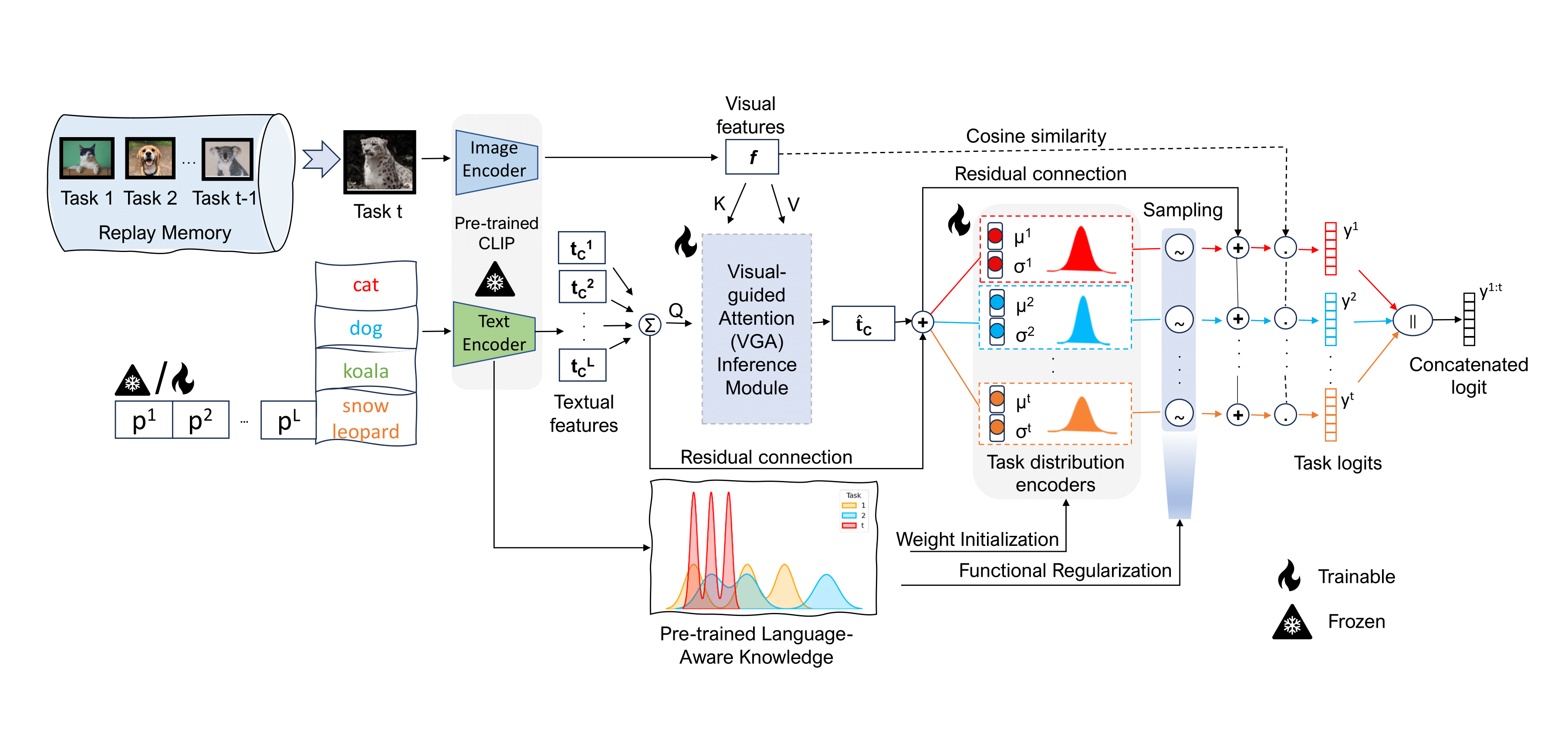
CLAP4CLIP: Continual Learning with Probabilistic Finetuning for Vision-Language Models
Continual learning (CL) aims to help deep neural networks to learn new knowledge while retaining what has been learned. Recently, pre-trained vision-language models such as CLIP, with powerful generalization ability, have been gaining traction as practical CL candidates. However, the domain mismatch between the pre-training and the downstream CL tasks calls for finetuning of the CLIP on the latter. The deterministic nature of the existing finetuning methods makes them overlook the many possible interactions across the modalities and deems them unsafe for high-risk CL tasks requiring reliable uncertainty estimation. To address these, our work proposes Continual LeArning with Probabilistic finetuning (CLAP). CLAP develops probabilistic modeling over task-specific modules with visual-guided text features, providing more reliable fine-tuning in CL. It further alleviates forgetting by exploiting the rich pre-trained knowledge of CLIP for weight initialization and distribution regularization of task-specific modules. Cooperating with the diverse range of existing prompting methods, CLAP can surpass the predominant deterministic finetuning approaches for CL with CLIP. Lastly, we study the superior uncertainty estimation abilities of CLAP for novel data detection and exemplar selection within CL setups. Our code is available at \url{https://github.com/srvCodes/clap4clip}.
PDF Abstract

 CIFAR-100
CIFAR-100
 CUB-200-2011
CUB-200-2011
 ImageNet-R
ImageNet-R
