ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition
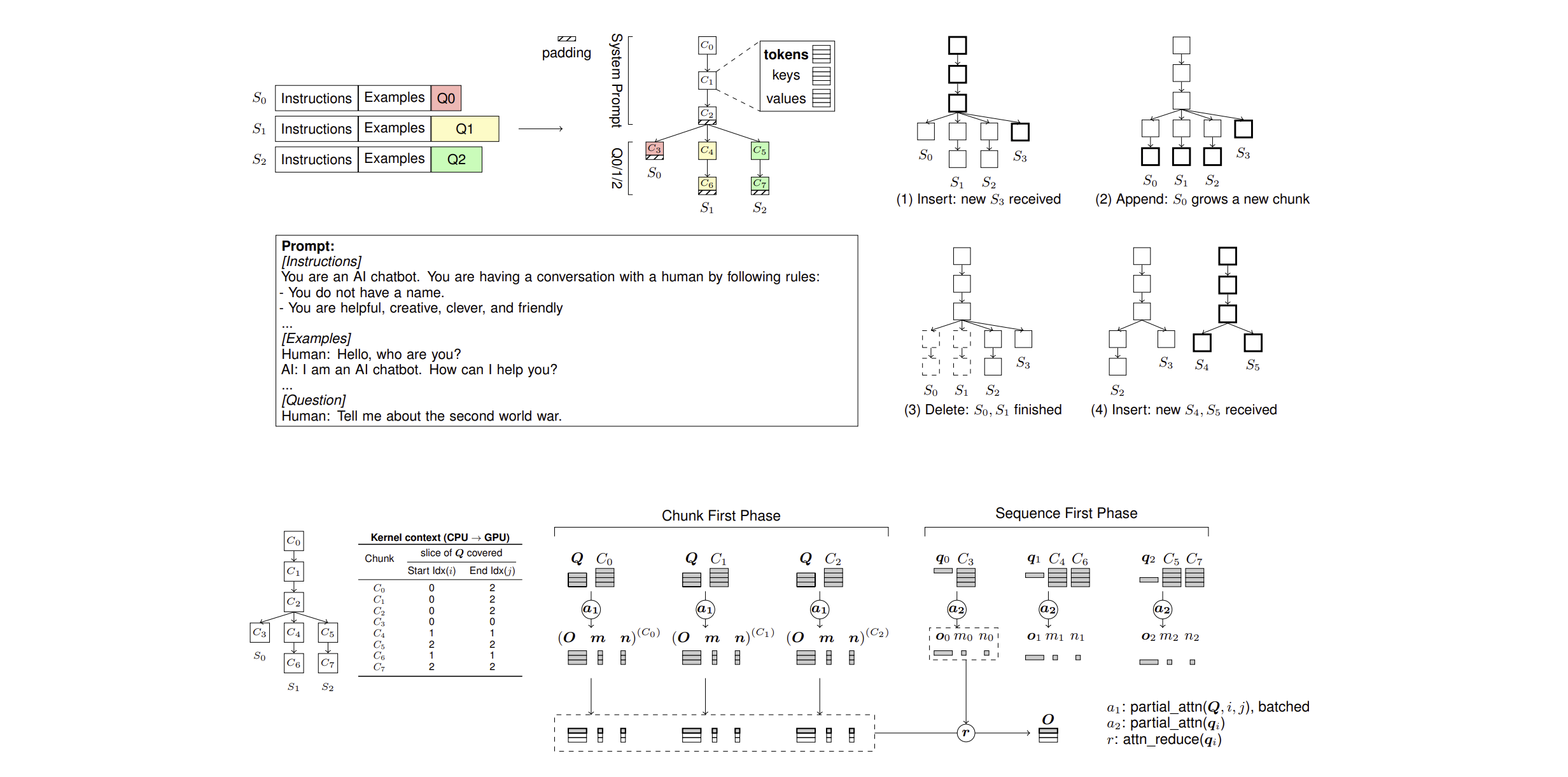
Self-attention is an essential component of large language models(LLMs) but a significant source of inference latency for long sequences. In multi-tenant LLMs serving scenarios, the compute and memory operation cost of self-attention can be optimized by using the probability that multiple LLM requests have shared system prompts in prefixes. In this paper, we introduce ChunkAttention, a prefix-aware self-attention module that can detect matching prompt prefixes across multiple requests and share their key/value tensors in memory at runtime to improve the memory utilization of KV cache. This is achieved by breaking monolithic key/value tensors into smaller chunks and structuring them into the auxiliary prefix tree. Consequently, on top of the prefix-tree based KV cache, we design an efficient self-attention kernel, where a two-phase partition algorithm is implemented to improve the data locality during self-attention computation in the presence of shared system prompts. Experiments show that ChunkAttention can speed up the self-attention kernel by 3.2-4.8$\times$ compared to the start-of-the-art implementation, with the length of the system prompt ranging from 1024 to 4096.
PDF Abstract
 ToolQA
ToolQA
