Chunk-aware Alignment and Lexical Constraint for Visual Entailment with Natural Language Explanations
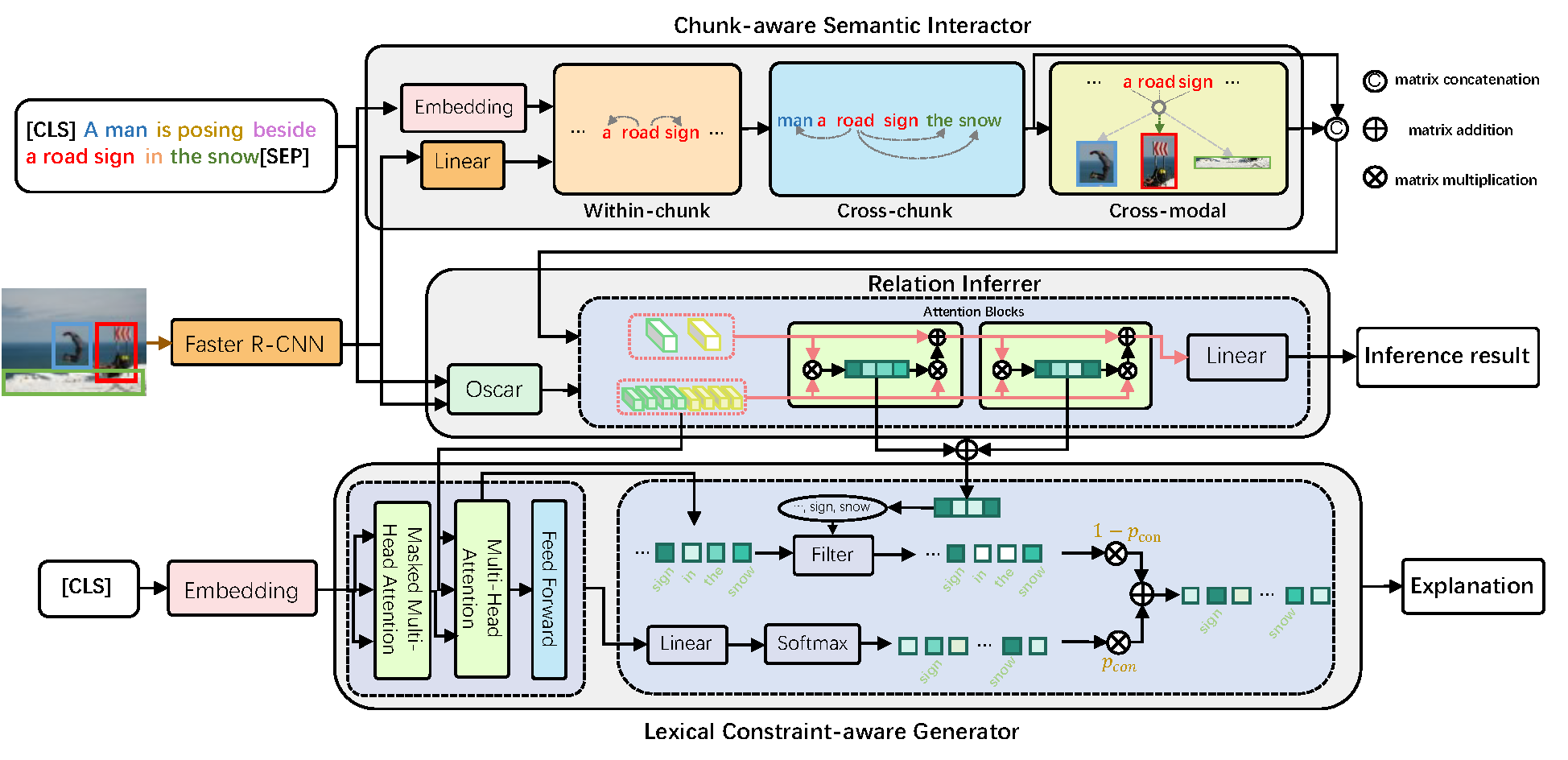
Visual Entailment with natural language explanations aims to infer the relationship between a text-image pair and generate a sentence to explain the decision-making process. Previous methods rely mainly on a pre-trained vision-language model to perform the relation inference and a language model to generate the corresponding explanation. However, the pre-trained vision-language models mainly build token-level alignment between text and image yet ignore the high-level semantic alignment between the phrases (chunks) and visual contents, which is critical for vision-language reasoning. Moreover, the explanation generator based only on the encoded joint representation does not explicitly consider the critical decision-making points of relation inference. Thus the generated explanations are less faithful to visual-language reasoning. To mitigate these problems, we propose a unified Chunk-aware Alignment and Lexical Constraint based method, dubbed as CALeC. It contains a Chunk-aware Semantic Interactor (arr. CSI), a relation inferrer, and a Lexical Constraint-aware Generator (arr. LeCG). Specifically, CSI exploits the sentence structure inherent in language and various image regions to build chunk-aware semantic alignment. Relation inferrer uses an attention-based reasoning network to incorporate the token-level and chunk-level vision-language representations. LeCG utilizes lexical constraints to expressly incorporate the words or chunks focused by the relation inferrer into explanation generation, improving the faithfulness and informativeness of the explanations. We conduct extensive experiments on three datasets, and experimental results indicate that CALeC significantly outperforms other competitor models on inference accuracy and quality of generated explanations.
PDF Abstract



 SNLI
SNLI
 Flickr30k
Flickr30k
 VCR
VCR
 e-SNLI-VE
e-SNLI-VE
 e-ViL
e-ViL
