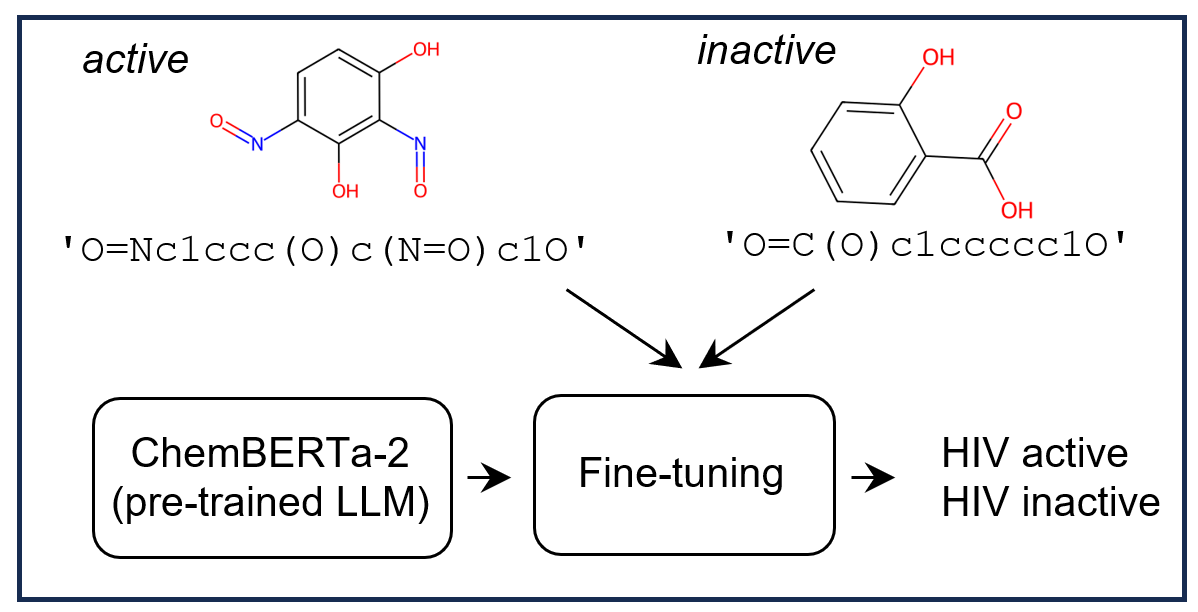
ChemBERTa: Large-Scale Self-Supervised Pretraining for Molecular Property Prediction
GNNs and chemical fingerprints are the predominant approaches to representing molecules for property prediction. However, in NLP, transformers have become the de-facto standard for representation learning thanks to their strong downstream task transfer. In parallel, the software ecosystem around transformers is maturing rapidly, with libraries like HuggingFace and BertViz enabling streamlined training and introspection. In this work, we make one of the first attempts to systematically evaluate transformers on molecular property prediction tasks via our ChemBERTa model. ChemBERTa scales well with pretraining dataset size, offering competitive downstream performance on MoleculeNet and useful attention-based visualization modalities. Our results suggest that transformers offer a promising avenue of future work for molecular representation learning and property prediction. To facilitate these efforts, we release a curated dataset of 77M SMILES from PubChem suitable for large-scale self-supervised pretraining.
PDF Abstract
 Colab
Colab


 MoleculeNet
MoleculeNet
