MR-GSM8K: A Meta-Reasoning Revolution in Large Language Model Evaluation
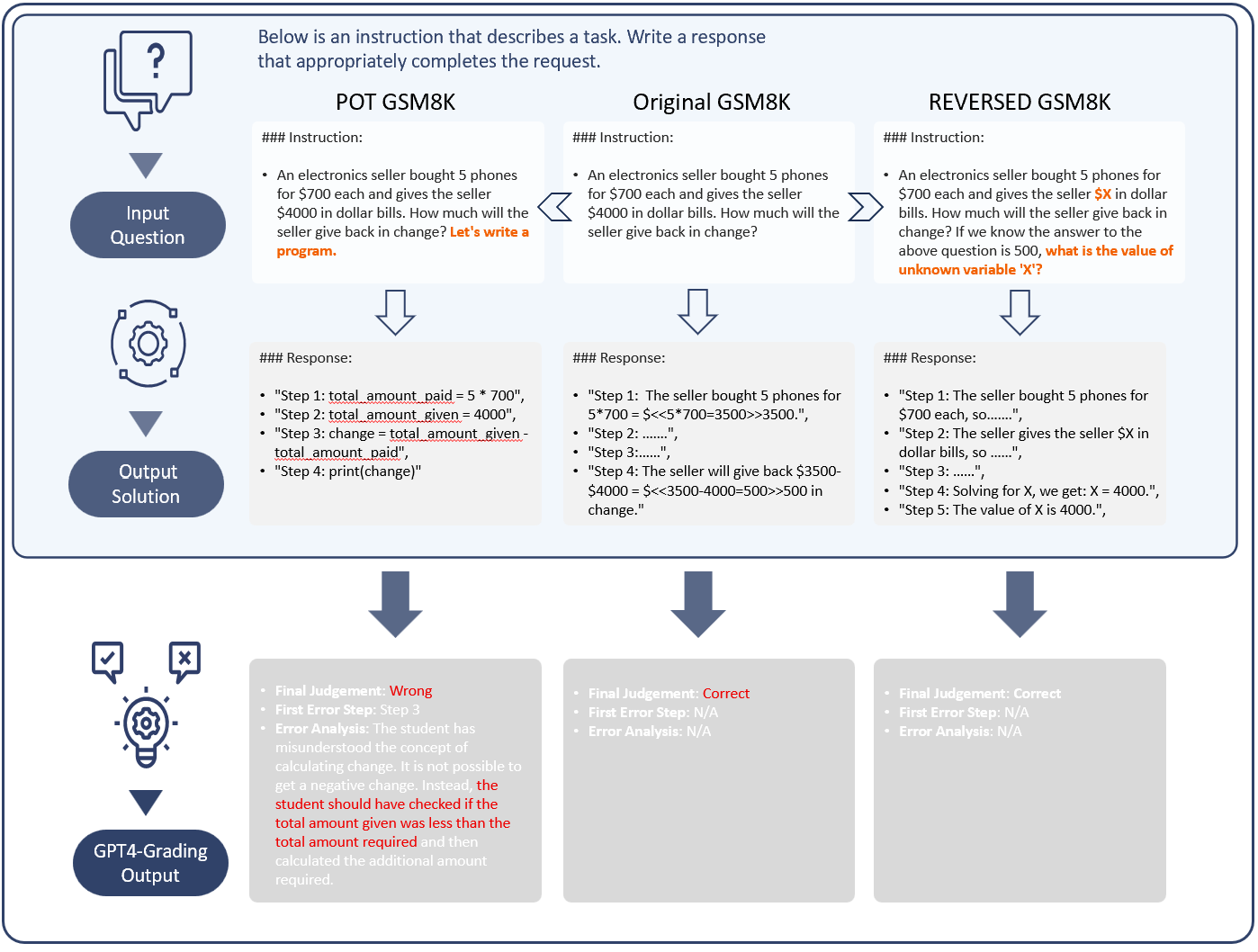
In this work, we introduce a novel evaluation paradigm for Large Language Models, one that challenges them to engage in meta-reasoning. This approach addresses critical shortcomings in existing math problem-solving benchmarks, traditionally used to evaluate the cognitive capabilities of agents. Our paradigm shifts the focus from result-oriented assessments, which often overlook the reasoning process, to a more holistic evaluation that effectively differentiates the cognitive capabilities among models. For example, in our benchmark, GPT-4 demonstrates a performance five times better than GPT3-5. The significance of this new paradigm lies in its ability to reveal potential cognitive deficiencies in LLMs that current benchmarks, such as GSM8K, fail to uncover due to their saturation and lack of effective differentiation among varying reasoning abilities. Our comprehensive analysis includes several state-of-the-art math models from both open-source and closed-source communities, uncovering fundamental deficiencies in their training and evaluation approaches. This paper not only advocates for a paradigm shift in the assessment of LLMs but also contributes to the ongoing discourse on the trajectory towards Artificial General Intelligence (AGI). By promoting the adoption of meta-reasoning evaluation methods similar to ours, we aim to facilitate a more accurate assessment of the true cognitive abilities of LLMs.
PDF Abstract


 GSM8K
GSM8K
 MATH
MATH
