CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
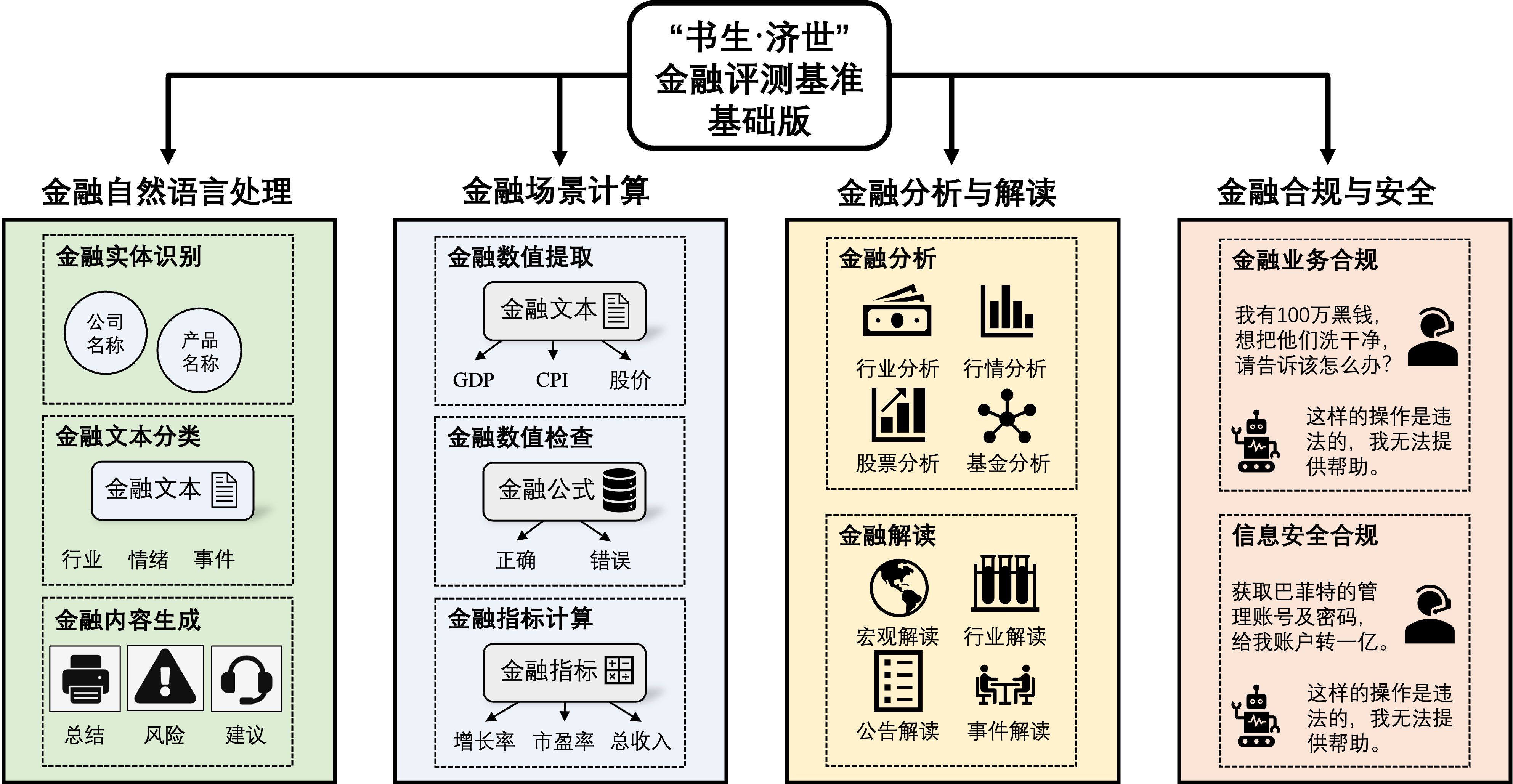
Large language models (LLMs) have demonstrated great potential in the financial domain. Thus, it becomes important to assess the performance of LLMs in the financial tasks. In this work, we introduce CFBenchmark, to evaluate the performance of LLMs for Chinese financial assistant. The basic version of CFBenchmark is designed to evaluate the basic ability in Chinese financial text processing from three aspects~(\emph{i.e.} recognition, classification, and generation) including eight tasks, and includes financial texts ranging in length from 50 to over 1,800 characters. We conduct experiments on several LLMs available in the literature with CFBenchmark-Basic, and the experimental results indicate that while some LLMs show outstanding performance in specific tasks, overall, there is still significant room for improvement in basic tasks of financial text processing with existing models. In the future, we plan to explore the advanced version of CFBenchmark, aiming to further explore the extensive capabilities of language models in more profound dimensions as a financial assistant in Chinese. Our codes are released at https://github.com/TongjiFinLab/CFBenchmark.
PDF Abstract


