CCC-wav2vec 2.0: Clustering aided Cross Contrastive Self-supervised learning of speech representations
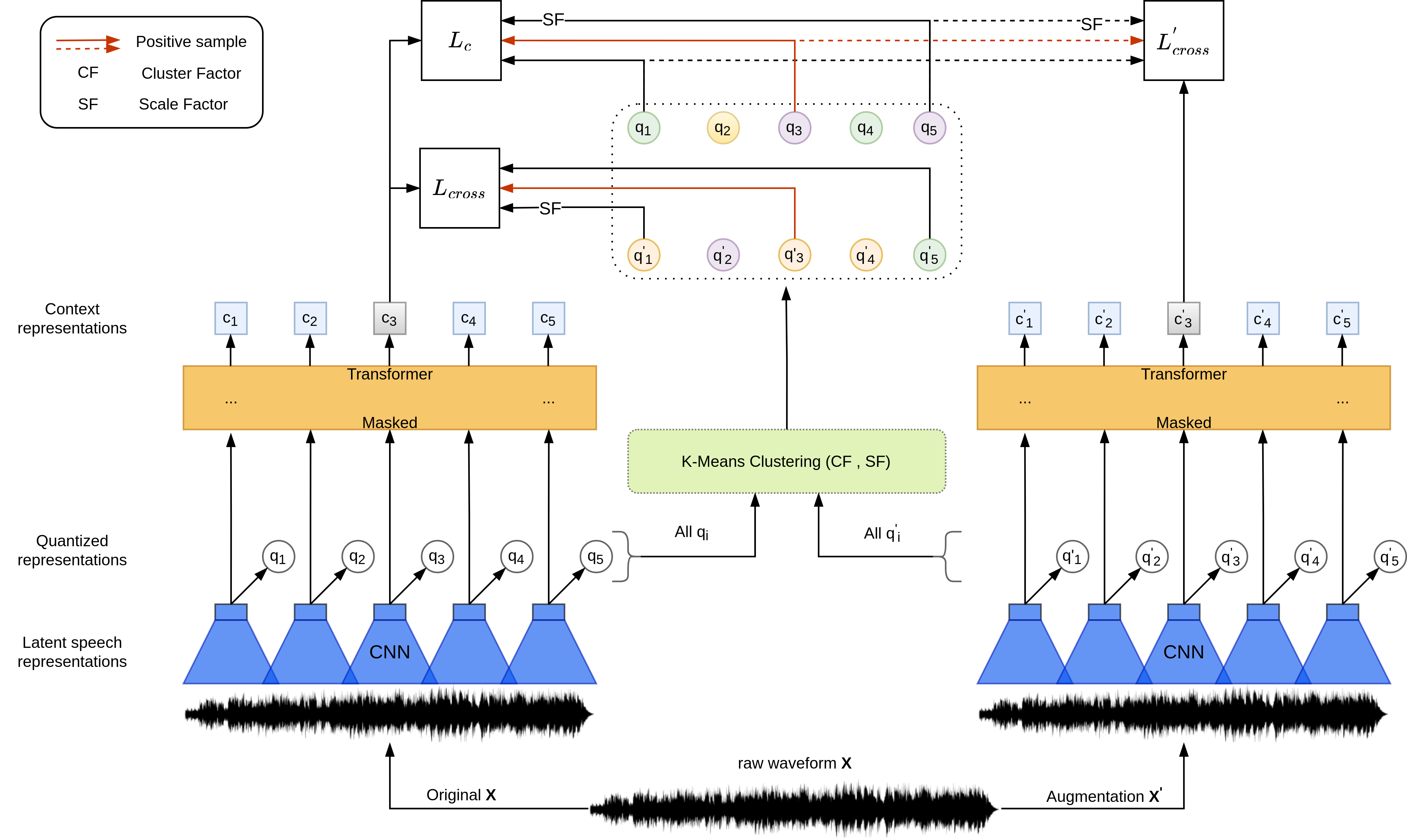
While Self-Supervised Learning has helped reap the benefit of the scale from the available unlabeled data, the learning paradigms are continuously being bettered. We present a new pre-training strategy named ccc-wav2vec 2.0, which uses clustering and an augmentation-based cross-contrastive loss as its self-supervised objective. Through the clustering module, we scale down the influence of those negative examples that are highly similar to the positive. The Cross-Contrastive loss is computed between the encoder output of the original sample and the quantizer output of its augmentation and vice-versa, bringing robustness to the pre-training strategy. ccc-wav2vec 2.0 achieves up to 15.6% and 12.7% relative WER improvement over the baseline wav2vec 2.0 on the test-clean and test-other sets, respectively, of LibriSpeech, without the use of any language model. The proposed method also achieves up to 14.9% relative WER improvement over the baseline wav2vec 2.0 when fine-tuned on Switchboard data. We make all our codes publicly available on GitHub.
PDF Abstract



 LibriSpeech
LibriSpeech
