CATR: Combinatorial-Dependence Audio-Queried Transformer for Audio-Visual Video Segmentation
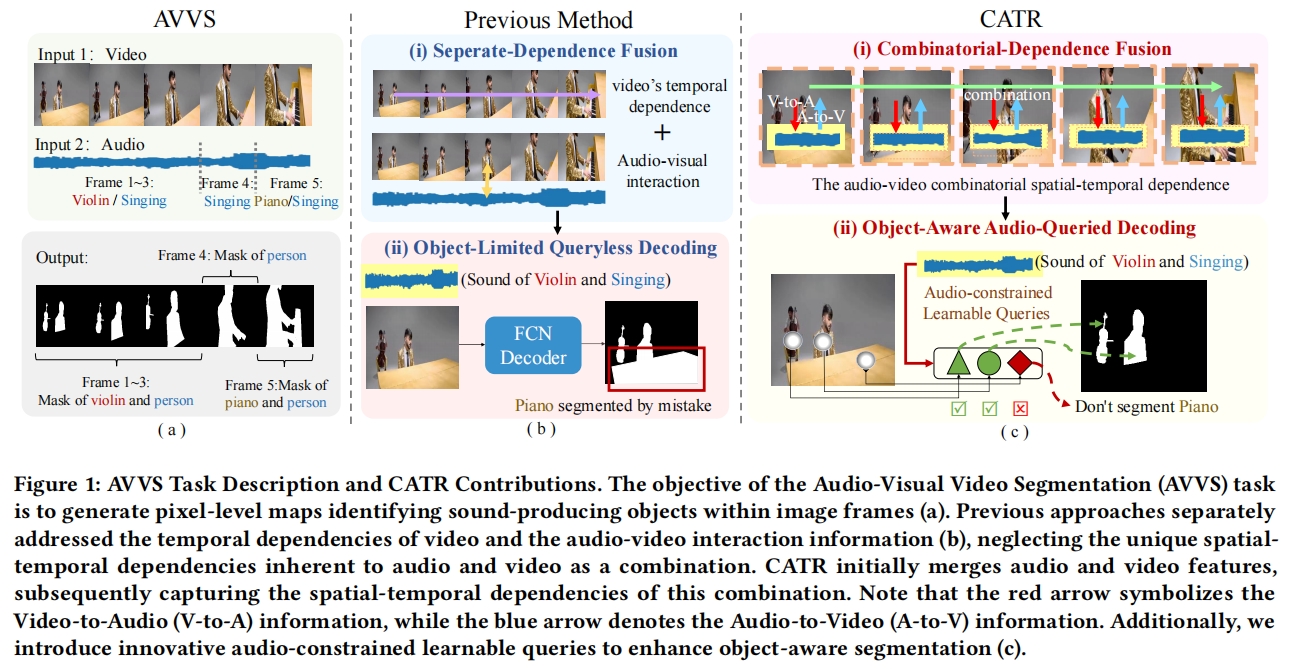
Audio-visual video segmentation~(AVVS) aims to generate pixel-level maps of sound-producing objects within image frames and ensure the maps faithfully adhere to the given audio, such as identifying and segmenting a singing person in a video. However, existing methods exhibit two limitations: 1) they address video temporal features and audio-visual interactive features separately, disregarding the inherent spatial-temporal dependence of combined audio and video, and 2) they inadequately introduce audio constraints and object-level information during the decoding stage, resulting in segmentation outcomes that fail to comply with audio directives. To tackle these issues, we propose a decoupled audio-video transformer that combines audio and video features from their respective temporal and spatial dimensions, capturing their combined dependence. To optimize memory consumption, we design a block, which, when stacked, enables capturing audio-visual fine-grained combinatorial-dependence in a memory-efficient manner. Additionally, we introduce audio-constrained queries during the decoding phase. These queries contain rich object-level information, ensuring the decoded mask adheres to the sounds. Experimental results confirm our approach's effectiveness, with our framework achieving a new SOTA performance on all three datasets using two backbones. The code is available at \url{https://github.com/aspirinone/CATR.github.io}
PDF Abstract

