CAST: Cross-Attention in Space and Time for Video Action Recognition
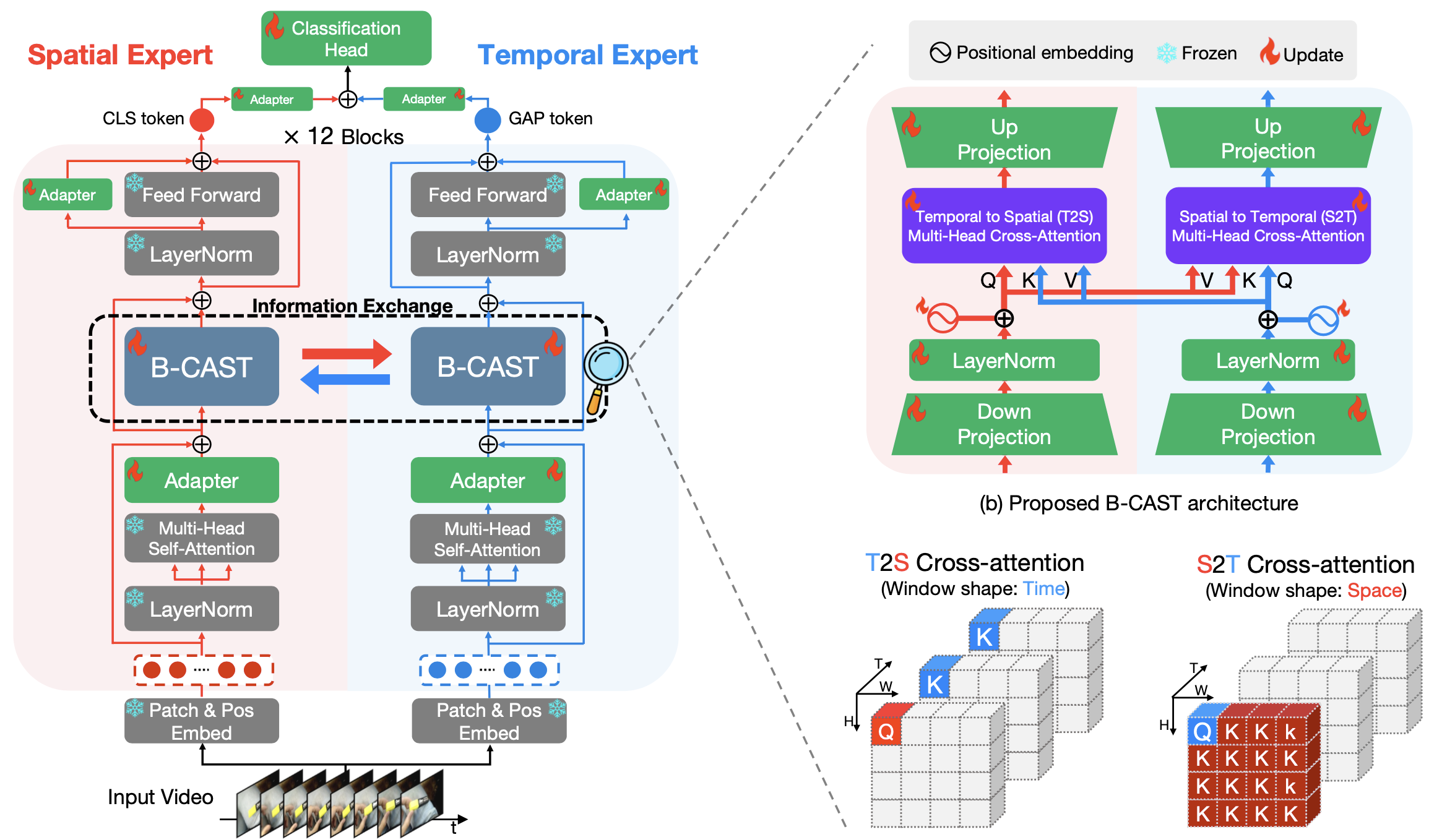
Recognizing human actions in videos requires spatial and temporal understanding. Most existing action recognition models lack a balanced spatio-temporal understanding of videos. In this work, we propose a novel two-stream architecture, called Cross-Attention in Space and Time (CAST), that achieves a balanced spatio-temporal understanding of videos using only RGB input. Our proposed bottleneck cross-attention mechanism enables the spatial and temporal expert models to exchange information and make synergistic predictions, leading to improved performance. We validate the proposed method with extensive experiments on public benchmarks with different characteristics: EPIC-KITCHENS-100, Something-Something-V2, and Kinetics-400. Our method consistently shows favorable performance across these datasets, while the performance of existing methods fluctuates depending on the dataset characteristics.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract



 Kinetics
Kinetics
 Kinetics 400
Kinetics 400
 Something-Something V2
Something-Something V2
 EPIC-KITCHENS-100
EPIC-KITCHENS-100

