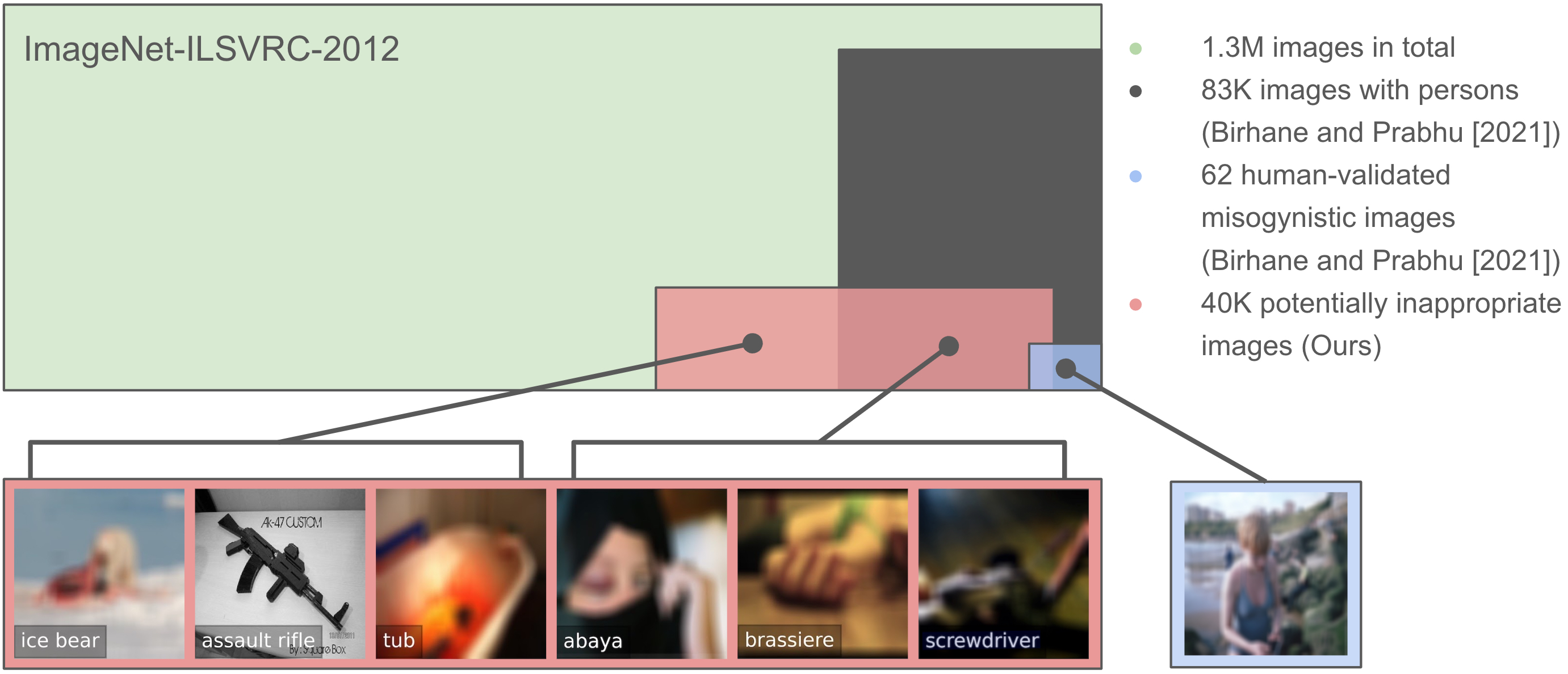
Can Machines Help Us Answering Question 16 in Datasheets, and In Turn Reflecting on Inappropriate Content?
Large datasets underlying much of current machine learning raise serious issues concerning inappropriate content such as offensive, insulting, threatening, or might otherwise cause anxiety. This calls for increased dataset documentation, e.g., using datasheets. They, among other topics, encourage to reflect on the composition of the datasets. So far, this documentation, however, is done manually and therefore can be tedious and error-prone, especially for large image datasets. Here we ask the arguably "circular" question of whether a machine can help us reflect on inappropriate content, answering Question 16 in Datasheets. To this end, we propose to use the information stored in pre-trained transformer models to assist us in the documentation process. Specifically, prompt-tuning based on a dataset of socio-moral values steers CLIP to identify potentially inappropriate content, therefore reducing human labor. We then document the inappropriate images found using word clouds, based on captions generated using a vision-language model. The documentations of two popular, large-scale computer vision datasets -- ImageNet and OpenImages -- produced this way suggest that machines can indeed help dataset creators to answer Question 16 on inappropriate image content.
PDF Abstract Colab
Colab


 ImageNet
ImageNet
 WebText
WebText
