Can Language Models Teach Weaker Agents? Teacher Explanations Improve Students via Personalization
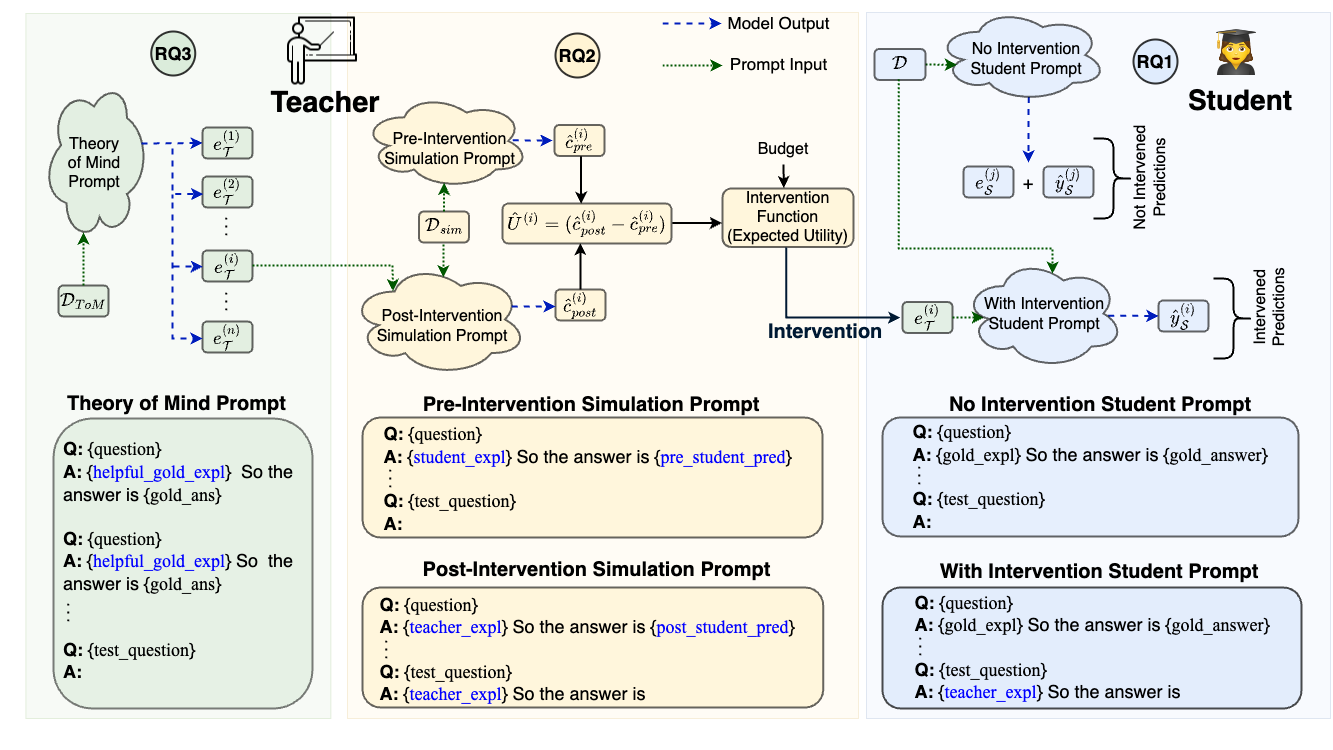
A hallmark property of explainable AI models is the ability to teach other agents, communicating knowledge of how to perform a task. While Large Language Models perform complex reasoning by generating explanations for their predictions, it is unclear whether they also make good teachers for weaker agents. To address this, we consider a student-teacher framework between two LLM agents and study if, when, and how the teacher should intervene with natural language explanations to improve the student's performance. Since communication is expensive, we define a budget such that the teacher only communicates explanations for a fraction of the data, after which the student should perform well on its own. We decompose the teaching problem along four axes: (1) if teacher's test time intervention improve student predictions, (2) when it is worth explaining a data point, (3) how the teacher should personalize explanations to better teach the student, and (4) if teacher explanations also improve students on future unexplained data. We first show that teacher LLMs can indeed intervene on student reasoning to improve their performance. Next, inspired by the Theory of Mind abilities of effective teachers, we propose building two few-shot mental models of the student. The first model defines an Intervention Function that simulates the utility of an intervention, allowing the teacher to intervene when this utility is the highest and improving student performance at lower budgets. The second model enables the teacher to personalize explanations for a particular student and outperform unpersonalized teachers. We also demonstrate that in multi-turn interactions, teacher explanations generalize and learning from explained data improves student performance on future unexplained data. Finally, we verify that misaligned teachers can lower student performance to random chance by intentionally misleading them.
PDF Abstract
 GSM8K
GSM8K
 CommonsenseQA
CommonsenseQA
 StrategyQA
StrategyQA
