Can Foundation Models Help Us Achieve Perfect Secrecy?
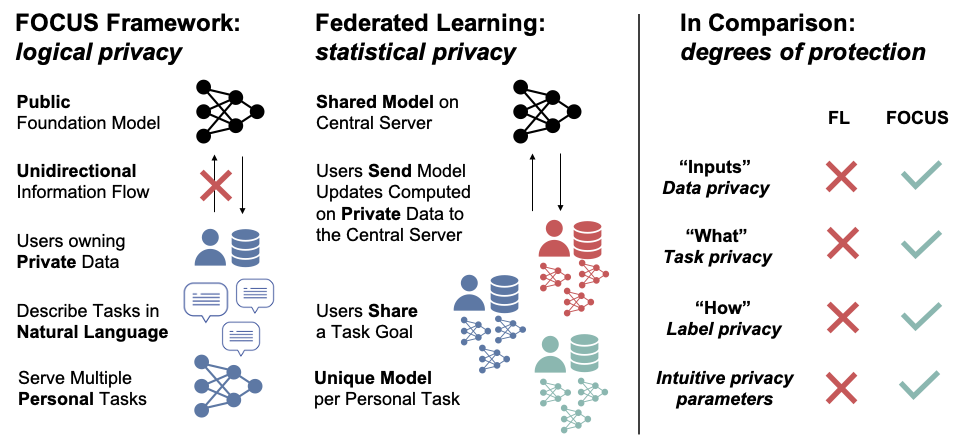
A key promise of machine learning is the ability to assist users with personal tasks. Because the personal context required to make accurate predictions is often sensitive, we require systems that protect privacy. A gold standard privacy-preserving system will satisfy perfect secrecy, meaning that interactions with the system provably reveal no private information. However, privacy and quality appear to be in tension in existing systems for personal tasks. Neural models typically require copious amounts of training to perform well, while individual users typically hold a limited scale of data, so federated learning (FL) systems propose to learn from the aggregate data of multiple users. FL does not provide perfect secrecy, but rather practitioners apply statistical notions of privacy -- i.e., the probability of learning private information about a user should be reasonably low. The strength of the privacy guarantee is governed by privacy parameters. Numerous privacy attacks have been demonstrated on FL systems and it can be challenging to reason about the appropriate privacy parameters for a privacy-sensitive use case. Therefore our work proposes a simple baseline for FL, which both provides the stronger perfect secrecy guarantee and does not require setting any privacy parameters. We initiate the study of when and where an emerging tool in ML -- the in-context learning abilities of recent pretrained models -- can be an effective baseline alongside FL. We find in-context learning is competitive with strong FL baselines on 6 of 7 popular benchmarks from the privacy literature and a real-world case study, which is disjoint from the pretraining data. We release our code here: https://github.com/simran-arora/focus
PDF Abstract

