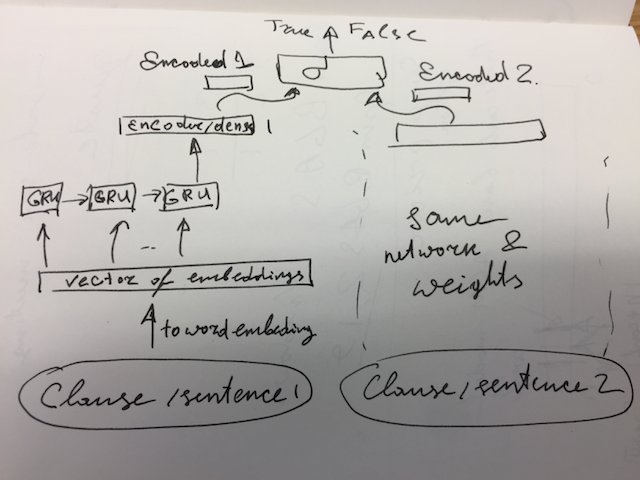
Calculating the similarity between words and sentences using a lexical database and corpus statistics
Calculating the semantic similarity between sentences is a long dealt problem in the area of natural language processing. The semantic analysis field has a crucial role to play in the research related to the text analytics. The semantic similarity differs as the domain of operation differs. In this paper, we present a methodology which deals with this issue by incorporating semantic similarity and corpus statistics. To calculate the semantic similarity between words and sentences, the proposed method follows an edge-based approach using a lexical database. The methodology can be applied in a variety of domains. The methodology has been tested on both benchmark standards and mean human similarity dataset. When tested on these two datasets, it gives highest correlation value for both word and sentence similarity outperforming other similar models. For word similarity, we obtained Pearson correlation coefficient of 0.8753 and for sentence similarity, the correlation obtained is 0.8794.
PDF Abstract

