BSL: Understanding and Improving Softmax Loss for Recommendation
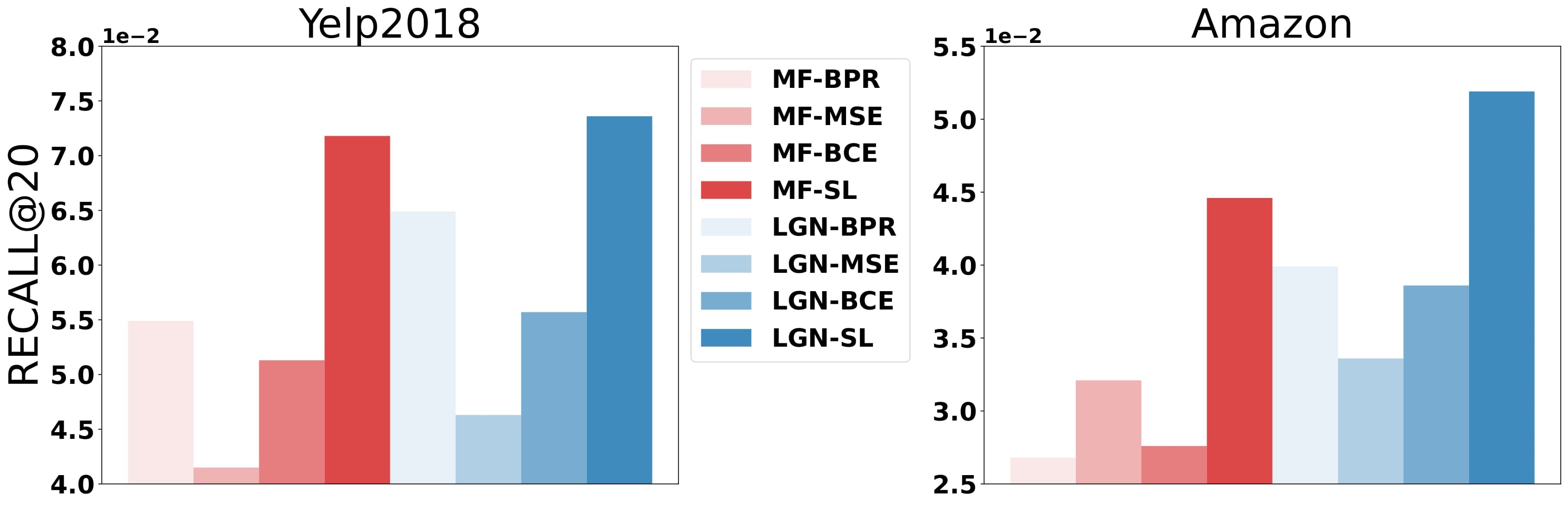
Loss functions steer the optimization direction of recommendation models and are critical to model performance, but have received relatively little attention in recent recommendation research. Among various losses, we find Softmax loss (SL) stands out for not only achieving remarkable accuracy but also better robustness and fairness. Nevertheless, the current literature lacks a comprehensive explanation for the efficacy of SL. Toward addressing this research gap, we conduct theoretical analyses on SL and uncover three insights: 1) Optimizing SL is equivalent to performing Distributionally Robust Optimization (DRO) on the negative data, thereby learning against perturbations on the negative distribution and yielding robustness to noisy negatives. 2) Comparing with other loss functions, SL implicitly penalizes the prediction variance, resulting in a smaller gap between predicted values and and thus producing fairer results. Building on these insights, we further propose a novel loss function Bilateral SoftMax Loss (BSL) that extends the advantage of SL to both positive and negative sides. BSL augments SL by applying the same Log-Expectation-Exp structure to positive examples as is used for negatives, making the model robust to the noisy positives as well. Remarkably, BSL is simple and easy-to-implement -- requiring just one additional line of code compared to SL. Experiments on four real-world datasets and three representative backbones demonstrate the effectiveness of our proposal. The code is available at https://github.com/junkangwu/BSL
PDF Abstract

 Yelp2018
Yelp2018
